简介
- InnoDB通过使用多版本并发控制(MVCC)来获得更高的并发性,并实现了SQL标准的四种隔离级别。
- 设计主要目标是面向在线事务处理(OLTP)
- 使用next-key-locking策略来避免幻读。
- 提供插入缓冲(insert buffer)、二次写(double write)、自适应哈希索引(adaptive hash index)、预读(read ahead)、刷新邻接页(Flush Neighbor Page)等高性能高可用的功能。
- 如果没有显式定义主键,引擎会生成一个6字节的row-id作为主键。
- InnoDB存储引擎是多线程模型,后台有多个不同的线程,负责处理不同的任务。
- 大量使用AIO来处理IO请求,这样可以极大提高数据库的性能。
- InnoDB是通过LSN(Log Seqence Number)来标记版本的。LSN是8个字节的数字。每个页、重做日志、Checkpoint都有LSN。
逻辑存储结构
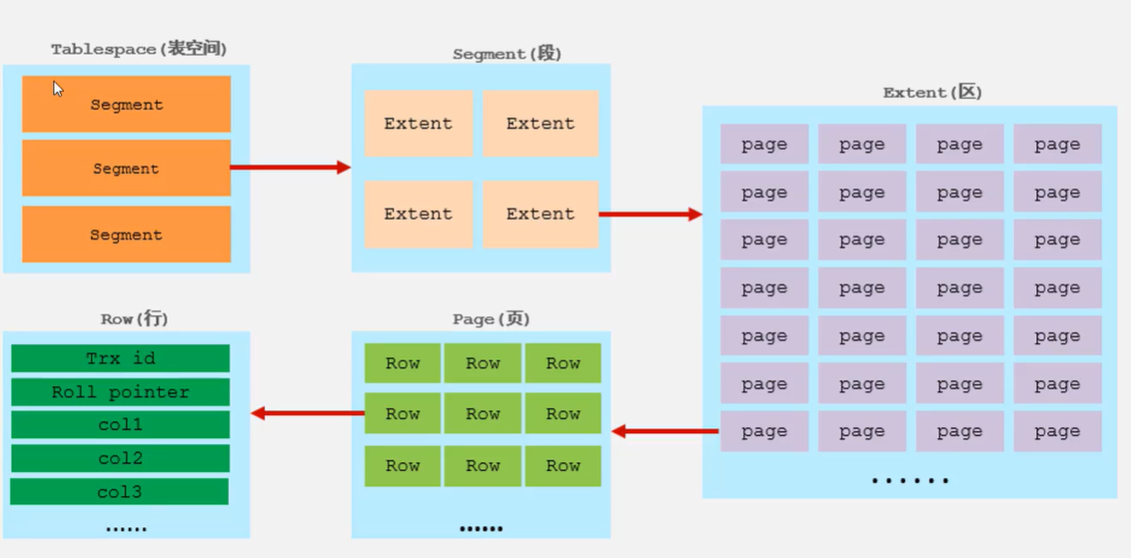
表空间(Tablespace)->段(Segment)->区(Extent)->页(Page)->(Row)行
表空间(ibd文件),一个mysql实例可以对应多个表空间,用于存储记录、索引等数据。
段,分为数据段(Leaf node segment)和索引段(Non-leaf node segment)、回滚段(Rollback segment),InnoDB是索引组织表,数据段就是B+数的叶子节点,索引段就是B+树的非叶子节点。段用来管理多个区。
区,表空间的单元结构,每个区的大小为1M,默认情况下,InnoDB存储引擎页大小为16KB,即一个区中共有64个连续的页。
页,InnoDB存储引擎磁盘管理的最小单元,每个页的大小默认为16KB。为了保证页的连续性,InnoDB存储引擎每次空磁盘申请4-5个区。
行,InnoDB存储引擎数据是按行进行存放的。Trx_id:每次对某条记录进行改动时,都会把对应的事务id赋值给trx_id隐藏列。Roll_pointer:每次对某条记录进行改动时,都会把旧的版本写入到undo日志中,然后这个隐藏列就相当于一个指针,可以通过它来找到该记录修改前的信息。
InnoDB架构
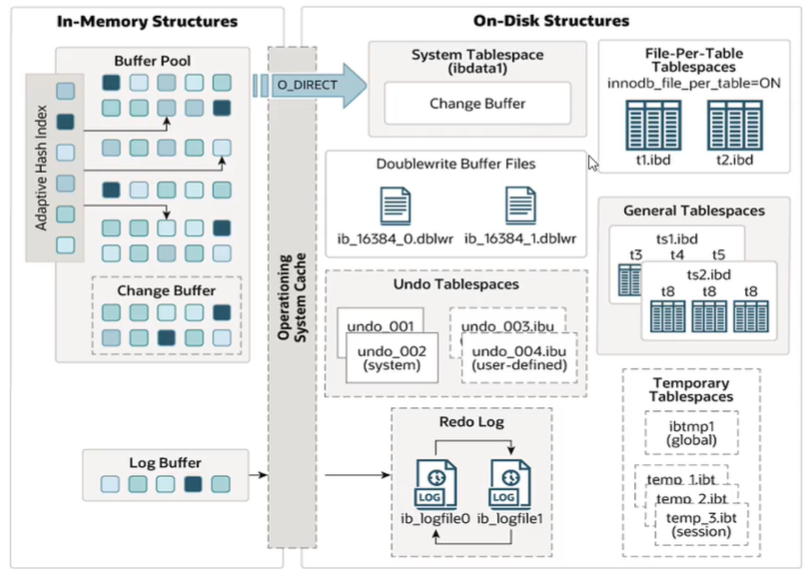
内存架构
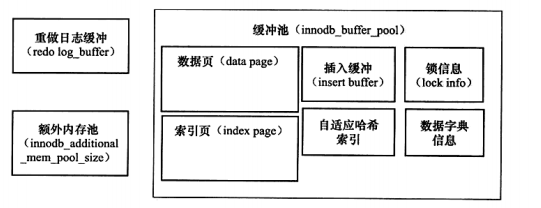
缓冲池
- InnoDB的记录按照页的方式进行管理,底层采用链表的数据结构进行管理。缓冲池就是一块内存区域,用来弥补磁盘速度慢对数据库性能的影响。
- 数据库读页操作时,先将磁盘读到的页放入缓冲池(将页FIX到缓冲池),下次在读取就走内存,内存没有就走磁盘。
- 对于页的修改,首先在缓冲池修改,然后再以一定的频率刷新到磁盘(不是每次页更新都会发生),而是通过一种Checkpoint的机制刷新回磁盘。减少磁盘IO,加快处理速度。
- 缓冲池的数据页类型有如下几种,索引页和数据页占的最多:
- 索引页
- 数据页
- undo页
- 插入缓冲
- 自适应哈希索引
- InnoDB存储的锁信息(lock info)
- 数据字典信息(data dictionary)
缓冲池以Page为单位,底层采用链表结构管理Page。根据状态可以将页分为三类:
- free page:空闲page,未被使用
- clean page:被使用未被修改
- dirty page:被使用且数据被修改过,数据与磁盘数据不一致
LRU List、Free List和Flush List
缓冲池是通过LRU算法进行进行管理的,页的大小默认为16KB。LRU列表用来管理已经读取的页,数据库刚启动是LRU列表是空的,这时的页都在Free列表里。
InnoDB 1.0.x之后支持压缩页的功能,将原本16KB的页压缩为1KB、2KB、4KB和8KB,非16KB的页通过unzip_LRU列表进行管理。
- LRU List(最近最少使用列表):
- LRU List是InnoDB的缓冲池中的数据页组织的方式,它按照数据页最近的使用情况来排序数据页。最常用的数据页会被放在列表的前部,而很少使用的数据页会在列表的末尾。
- 当需要读取数据页时,InnoDB会首先查找缓冲池中的LRU List,如果数据页已经在缓冲池中,它将被移动到列表的前部,表示最近使用过。
- 如果缓冲池已满,需要为新数据页腾出空间,InnoDB会选择LRU List中末尾的数据页进行替换,因为这些数据页表示最近最少使用的数据。
- Free List(空闲列表):
- Free List是InnoDB中用于管理未分配给数据页的缓冲池页的列表。当InnoDB需要为新数据页分配内存时,它会首先查找Free List上的空闲页。
- 如果Free List上没有足够的空闲页可供使用,InnoDB将尝试从操作系统申请新的内存页,并将其添加到Free List中。
- Flush List(刷新列表):
- Flush List是InnoDB中用于管理需要被刷写回磁盘的数据页的列表。这些数据页通常是已经被修改过的脏页(dirty pages),需要将其内容写回到磁盘以保持数据的持久性。
- InnoDB使用一种称为"脏页刷写策略"来决定何时将脏页刷新到磁盘。Flush List上的数据页将按照一定的策略被刷新到磁盘,通常会优先选择对系统性能影响较小的数据页。
在LRU列表中的页被修改后,该页被称为脏页(dirty page),这个时候数据库会通过checkpoint机制刷脏,而Flush列表即为脏页列表。
脏页同时存在于LRU列表和Flush列表,LRU用来管理缓冲池的可用性,Flush用来管理刷脏,二者互不影响。
更改缓冲区(在5.x版本之前叫做插入缓冲区)
针对于非唯一二级索引,在5.x版本之前叫做插入缓冲区,8版本之后叫做更改缓冲区。在执行DML语句时,如果这些数据Page没有在Buffer Pool中,不会直接修改磁盘,而是将数据变更保存在更改缓冲区里面。等待以后数据被读取时,再将数据合并到Buffer Pool中,然后再刷新到磁盘。
Change Buffer的意义:
和聚簇索引不同,二级索引通常是不唯一的,并且插入和删除的顺序是随机的,可能会影响索引树中不相邻的二级索引页,要是每次都操作磁盘就会造成大量的磁盘IO。所以我们把操作合并在Change Bufer里面,减少磁盘IO。
自适应hash
自适应hash索引用于单条数据的查询优化,InnoDB会监控对表上索引页的查询,如果观察到可以用hash索引提升速度,那么就会自己建立hash索引,不需要人工干预,默认是开启的。
日志缓冲区
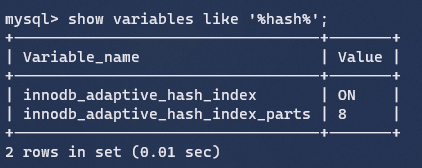
用来缓存日志(redo log、undo log),默认大小16M,日志缓冲区会定期刷新到磁盘,达到节省磁盘IO的目的。如果需要更新、插入、删除许多行的事务,可以增大该缓冲区节省磁盘IO。
innodb_log_buffer_size:缓冲区大小
innodb_flush_log_at_trx_commit:日志刷盘的时机,0表示每秒写入并刷盘,1表示每次事务提交时写入并刷盘,2表示每次事务提交后写入,并每秒刷盘。
InnoDB首先将重做日志放入这个缓冲区,然后按照一定的频率刷新到重做日志文件,该缓冲区不用设置很大,一般每一秒钟都会刷新日志文件,用户只需要保证每秒钟产生的事务量在这个大小之内即可。
下列三种情况会刷新重做日志:
- Master Thread每秒钟刷新重做日志
- 每个事务提交时
- 重做日志剩余空间小于一半时
磁盘架构
System Tablespace
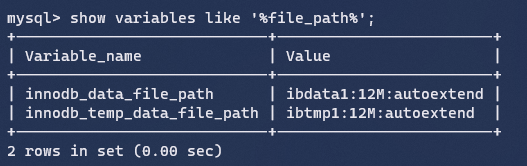
系统表空间是用来保存修改缓冲区的。如果表不是在每个独立表空间或者通用表空间中创建,它也会包含表和索引数据。(在MySQL5.x版本中还包含InnoDB数据字典、undolog等)。
参数:
innodb_data_file_path:系统表空间的存储路径
File Per Table Tabspace
每个表的独立表空间,包含单个表的数据和索引,存储在文件系统上的单个数据文件中,默认是开启的。开启后每个数据库都会有一个独立的文件夹(如下图,是三个不同数据库的文件夹):

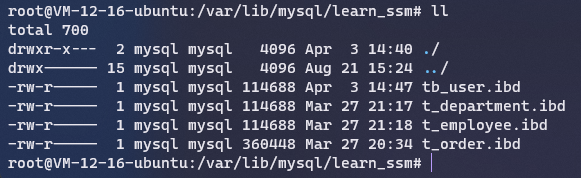
每个表都会有一个独立的ibd文件(下图是learn_ssm数据库的表文件):
参数:innodb_file_per_table
General Tablespce
通用表空间,需要自己手动创建,后续建表可以指定使用该表空间,一般很少用。
创建表空间语法:
CREATE TABLESPACE 表空间名称 ADD DATAFILE '表文件名' ENGINE = 'innodb';指定表空间语法:
CREATE TABLE (xxx) ENGINE=innodb TABLESPACE 表空间名称创建测试表空间:

创建成功之后,在mysql目录下可以找到test.ibd文件:

Undo Tablespace
撤销表空间,MySQL实例在初始化时会自动创建两个默认的undo表空间(初始大小16M),用于存储undo log日志。
在MySQL目录下可以找到这两个文件:

Temp Tablespace
主要用来存储用户创建的一些临时表。
Doublewrite Buffer Files
双写缓冲区,InnoDB引擎在刷脏前,会先将页写入到双写缓冲区文件里面,便于系统异常时恢复数据。
可以在MySQL目录下找到两个双写缓冲区文件:

Redo Log
重做日志,用来实现事务的持久性,由重做日志缓冲(在内存)和重做日志文件(在磁盘)两部分组成。当事务提交之后,会把所有的修改信息都存到该日志中,用于在刷脏发生错误时,进行数据恢复。RedoLog是循环写入的,不会永久保存。
后台线程
Master Thread
这是一个非常核心的线程,主要负责调度其他线程,将缓冲池的数据异步刷新到磁盘,保证数据一致性,包括刷脏、合并插入缓冲、UNDO页的回收等。
IO Thread
该线程主要负责AIO请求的回调处理。
| 线程类型 | 默认个数 | 职责 |
|---|---|---|
| Read thread | 4 | 负责读操作 |
| Write thread | 4 | 负责写操作 |
| Log thread | 1 | 将日志刷新到磁盘 |
| Insert buffer thread | 1 | 将写缓冲区内容刷新到磁盘 |
Purge Thread
用来回收已经使用并分配的undo页,从InnoDB1.1开始,purge操作可以独立到单独的线程来减轻Master Thread的工作。用户可以在配置文件添加如下命令来启动独立的purge线程:
[mysqld]
innodb_purge_thread=1Page Cleaner Thread
该线程是1.2.x版本引入的,单独用来做脏页刷新,减轻 Master Thread 的工作,减少阻塞。
索引
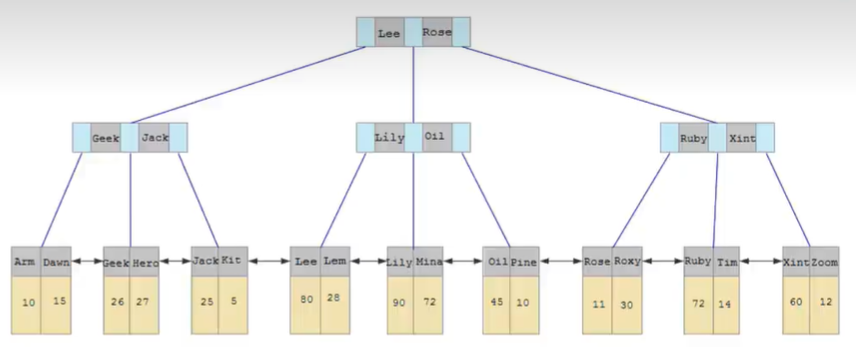
B-Tree(多路平衡查找树)
以一个颗最大度数(max-degree)为5的b树为例(每个节点最多存储4个key,5个指针,即五个分支):
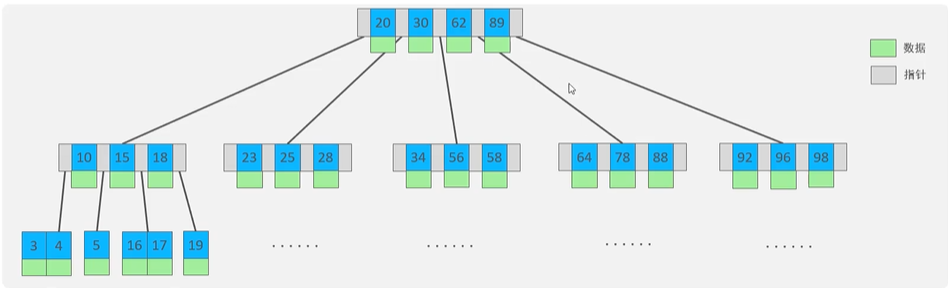
如果插入数据时,节点的key变成了5个,那么就会发生树的裂变,中间元素向上分裂,即中间元素会跑到父节点里面去(如果父节点key也变成了5个,那么也会分裂),左右两边别拆成两个子节点和父节点连接。
B+树
最大度数为4的B+树为例:
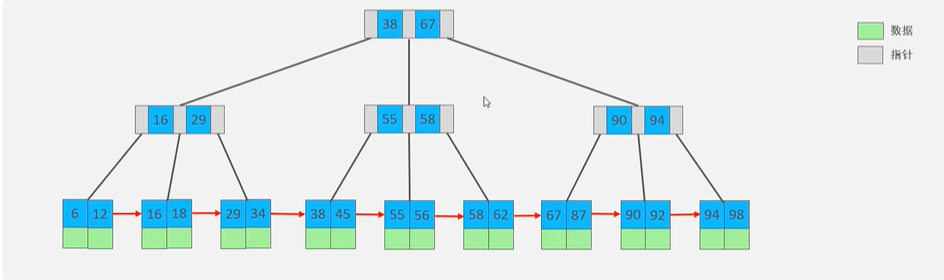
和B树最大的区别是,在向上分裂的过程中,中间元素在加入父节点的同时,不会从当前节点中删除,而是会保留在右边的节点。
在查找数据的过程中,非叶子节点只是起到索引的作用,所有数据都保存在叶子节点。
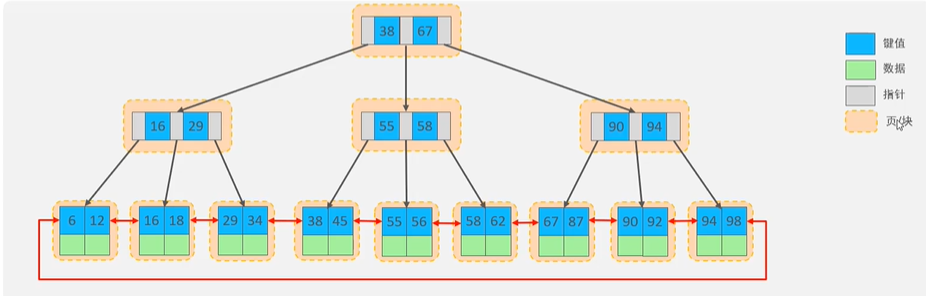
索引分类
| 分类 | 含义 | 特点 | 关键字 |
|---|---|---|---|
| 主键索引 | 主键 | 默认自动创建,只能有一个 | PRIMARY |
| 唯一索引 | 不能重复 | 可以有多个 | UNIQUE |
| 常规索引 | 快速定位,可以重复 | 可以有多个 | |
| 全文索引 | 查找到是文本的关键字,而不是比较索引的值 | 可以有多个 | FULLTEXT |
InnoDB的指针占用6个字节,如果主键为bigint,那么占8个字节。因为一页默认大小为16k,所以在索引页里面,假设主键数量为n,那么指针数量就是n+1,所以就得到:8n +6(n+1)=16k,得到 n= 1169,所以一个索引页大概能存储1169个主键,可以有1170个分支。
索引语法
# 创建索引,不加索引类型,默认就是常规索引,DESC | ASC为索引是降序还是升序
CREATE [UNIQUE | FULLTEXT] INDEX index_name ON table_name (index_col_name DESC | ASC,...);
# 查看索引
SHOW INDEX FROM table_name;
# 删除索引
DROP INDEX index_name ON table_name;
# 索引的命名规范一般是:idx_表名_字段名创建联合索引时,字段顺序是有讲究的。
索引失效
最左前缀法则
联合索引要遵循最左前缀法则:查询从索引的最左列开始,且不能跳过,如果跳过,索引将部分失效(只有左边连续的索引会有用),是否失效和查询顺序无关,跟是否存在有关。
索引失效情况
联合索引中,出现范围查询(>、<会失效,>=、<=不会),会导致范围查询右侧的列索引失效。
对索引列进行运算,索引失效。
字符串查询不加引号,索引失效(隐式类型转换,导致索引失效)。
模糊匹配时,尾部模糊不会失效,否则索引失效(可以字符串倒转,优化成尾部模糊)。
在使用 A or B时,A和B必须都是索引,否则索引失效。
索引失效情况(数据分布影响)
如果MySQL评估觉得全表扫描比索引快,则不使用索引 。
- a IS NOT NULL:如果a字段的非NULL数据较多,则全表扫描,否则走索引
- a IS NULL:和IS NOT NULL原理一样,如果NULL数据较多,则全表扫描,否则走索引
还有其他的情况,也会导致索引失效,如范围查询,如果查询的数据占表内数据大多数,则全表扫描,不会走索引(因为这种情况下索引会更慢)。
索引的使用
SQL提示(指定索引)
在SQL语句中加入一些人为提示,来达到优化的目的。
比如,一个字段创建了联合索引和单列索引,默认是MySQL自己选择使用哪个索引,但是我们可以通过SQL提示,自己规定走哪个索引。
# use index:建议数据库,使用哪个索引(不强制)
SELECT * FROM 表名 USE INDEX(索引名) WHERE 条件;
# ignore index:不使用哪个索引
SELECT * FROM 表名 IGNORE INDEX(索引名) WHERE 条件;
# force index:必须走哪个索引(强制)
SELECT * FROM 表名 FORCE INDEX(索引名) WHERE 条件;覆盖索引(避免回表)
尽量使用覆盖索引,即使用索引查询,并且返回的数据在该索引里都能找到,避免回表查询。减少使用select *。
是否回表可以通过查看Extra来得知,下面的查询没有回表,因为返回的数据,在都包括在查询条件的索引里面:

而这个查询进行了回表( Using index condition),因为返回的数据不能全都在索引里面找的到:

前缀索引
在类型为字符串(warchar、text等)时,有时候就需要索引很长的字符串,这就会让索引变得很大,查询时就会浪费大量磁盘IO。因此,我们可以只将数据的一部分前缀建立索引,大大节省索引空间,提高索引效率。
# n为前缀的长度
CREATE INDEX 索引名 ON 表名(索引名(n));前缀长度根据索引的选择性来决定,选择性 = 不重复的记录 / 总记录,比值越高,查询效率越高。
一般来说,前缀长度越短,选择性就越低,不过占用空间就越小,所以要根据具体业务来决定长度。
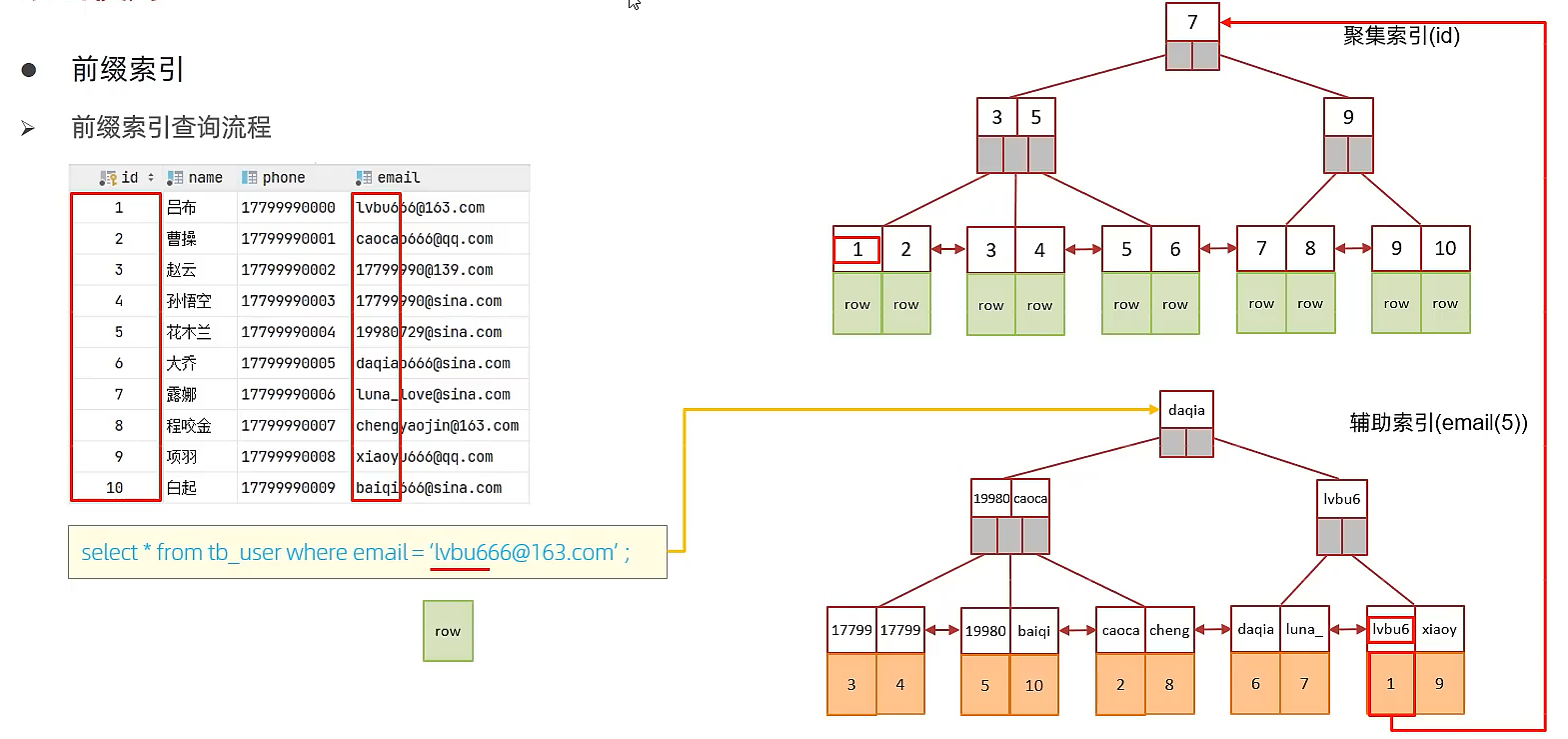
联合索引
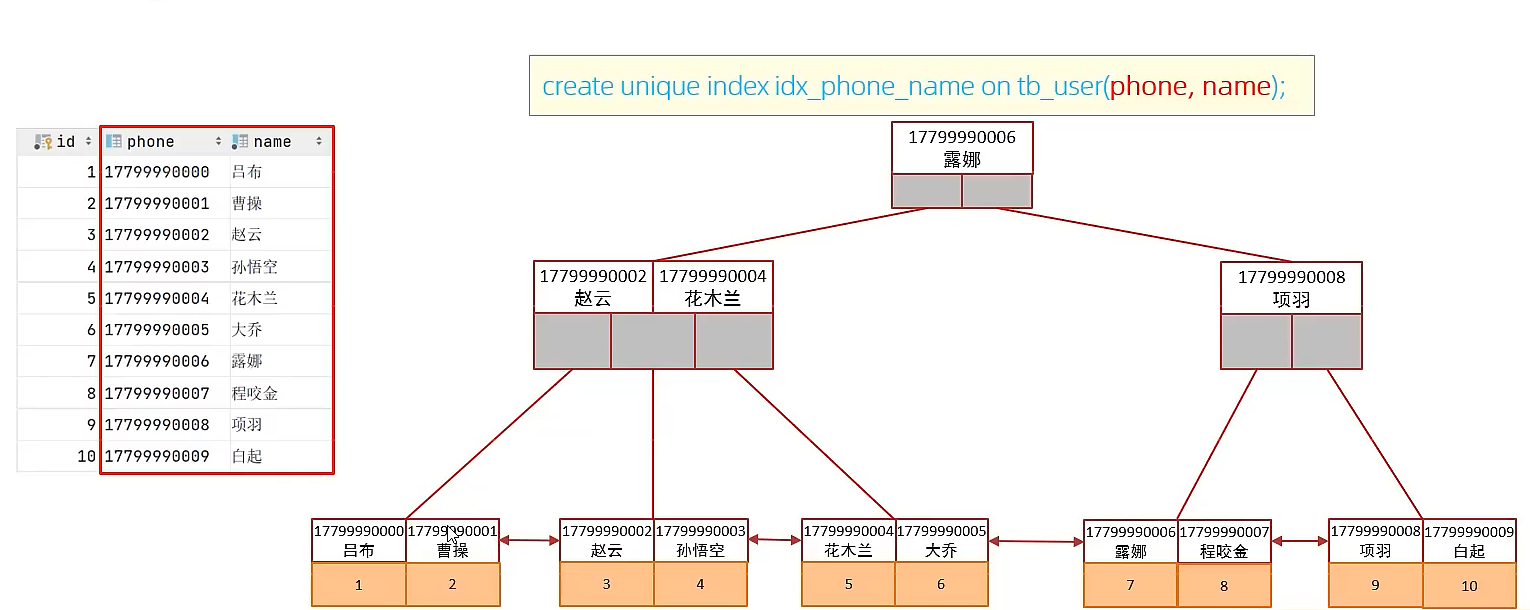
联合索引会把字段组合起来,组合起来排序。尽量使用联合索引,性能比较高,并且使用得当,可以避免回表查询,少使用单列索引。
在同时使用多个索引的情况时的情况,下图时索引情况:
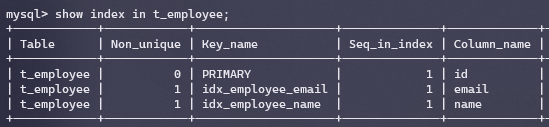
下面是使用or连接两个索引,发现使用两个索引,Using sort_union(idx_employee_name,idx_employee_email):

当用and连接的时候,MySQL会自动选择效率高的那个索引:

所以当我们查询字段比较多时,尽量使用联合索引,提高查询效率。在创建联合索引的时候,字段的顺序也很重要,需要根据最左匹配法则和字段查询频率,去决定联合索引的字段顺序。
索引设计原则
- 针对数据量大(超过100万)、查询频繁的表建立索引。
- 针对经常作为查询条件、排序、分组的字段建立索引。
- 尽量选择区分度高(选择性高)的列作为索引,尽量建立唯一索引,区分度越高,效率越高。
- 如果时字符串类型且很长,根据字段特点建立前缀索引。
- 尽量使用联合索引,尽量使用覆盖索引,避免回表。
- 控制索引数量,索引越多,索引维护的代价就越大,会影响增删改的效率和占用磁盘空间。
- 如果索引不能为NULL值,请在建表时添加NOT NULL约束,优化器会根据是否包含NULL值,来确定那个索引效率更高。
SQL性能分析
查看服务器状态
客户端可以通过 show [ session | global ] status 命令来查询服务器状态信息,可以查看当前数据库的INSERT、UPDATE、DELETE、SELECT的访问频率:
SHOW GLOBAL STATUS LIKE 'Com_______';#七个下划线慢查询日志
慢查询日志会记录所有执行时间超过了指定时间(long_query_time,默认10秒)的SQL语句,默认没有开启慢查询日志,需要自己更改配置(/etc/my.cnf)开启:
# 开启慢查询
slow_query_log=1
# 设置超时时间(秒)
long_query_time=2
# 慢查询日志地址:/var/lib/mysql/localhost-slow.logprofle详情
show profiles 会显示耗时详情,通过 hava_profiling 参数可以查看当前是否支持profile操作:
# 是否支持profile
SELECT @@have_profiling
# 是否开启
SELECT @profiling
# 开启profile
SET profiling=1;
# 查看当前会话的SQL耗时情况
SHOW profiles;
# 查看指定query_id 的SQL语句各个阶段的耗时情况
SHOW PROFILE FOR query query_id;
# 查看指定query_id 的SQL语句CPU使用情况
SHOW PROFILE cpu for query query_id;explain执行计划
上面都是在时间层面分析性能,但是这太粗略了,并不能真正评判SQL的性能。
explain可以查看SQL的执行计划,是否用到了索引,表的连接情况,表的连接顺序等。
# 直接在SELECT前面加上关键字:EXPLAIN | DESC,两个效果是一样的
EXPLAIN SELECT 字段列表 FROM 表名 WHERE 条件;查询结果:
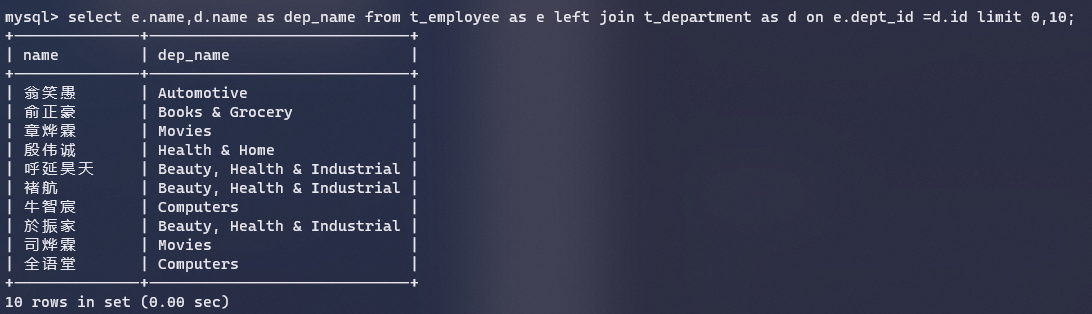
对应的explain:

| 字段名 | 含义 |
|---|---|
| id | select查询序号,表示查询中select子句或操作表的顺序,id值越大越先执行,id相同自上而下执行。 |
| select_type | 查询类型,SIMPLE(简单表,不连表或者子查询),PRIMARY(主查询,即外层查询)、UNION(UNION中的第二个或者后面的查询语句)、SUBQUERY(SELECT/WHERE之后包含了子查询)等。 |
| type | 表示连接类型,性能由好到差为:NULL(没有查表)、system(访问系统表)、const(根据主键或者唯一索引查表)、eq_ref(使用唯一索引或主键)、ref(使用非唯一索引查表)、range(范围查询)、index(用了索引,但是会扫描遍历索引树)、all(全表扫描) |
| posible_keys | 显示在这张表上可能用到的索引,一个或者多个 |
| key | 实际使用的索引 |
| key_len | 使用索引的字节数(索引字段的最大可能长度,并非实际长度) |
| rows | 执行查询的行数(预估值,不是百分百准确) |
| filtered | 返回结果的行数占需读取行数的百分比,越大越好 |
| extra | 额外信息 |
SQL优化
插入优化
如果我们插入多条数据,可以从下面几个点去优化:
批量插入(不建议超过1000条)
批量插入(不建议超过1000条),如果要插入几万条,我们就分成多条insert语句插入。不要一条一条插入,因为每一次insert都会和数据库进行一次连接,进行网络通讯,这个性能相对来说比较低。
手动提交事务
手动提交事务。因为默认是自动提交,当你执行一条insert之后,事务就提交了,再次insert会再开启新的事务,然后提交。这样会反复开启关闭事务,所以我们手动提交事务,所有insert都在一个事务内完成。
主键顺序插入
顺序插入性能高于随即插入,避免页的分裂与页的合并。
百万数据使用load
如果一次性插入一百万的数据,使用insert性能较低,此时可以使用load命令,一次性将本地文件的数据一次性加入到数据库表结构当中:
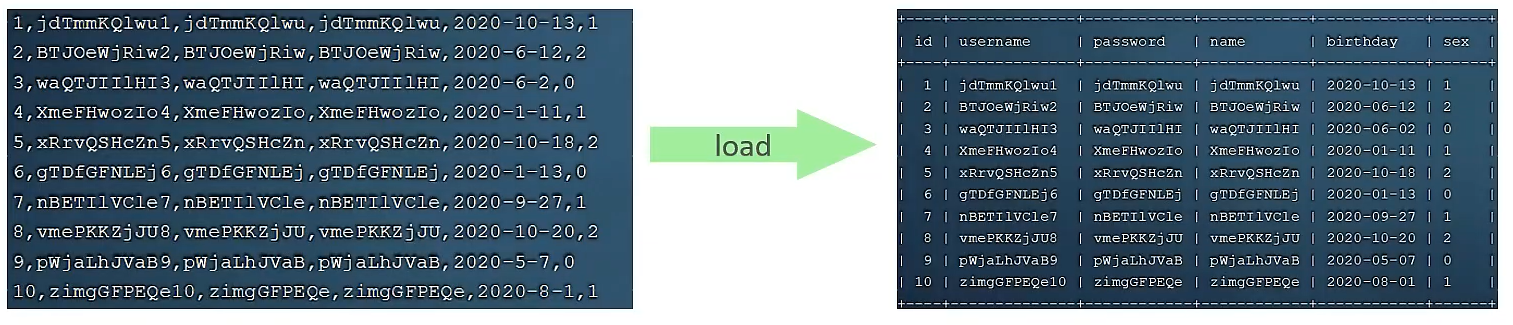
# 客户端连接服务器,加上参数:--local-infile
mysql --local-infile -uroot -p
# 设置全局参数 local_infile=1,开启本地加载数据的开关
set global local_infile=1;
# 执行load命令加载数据
load data local infile '数据文件绝对路径' into table '表名' fields terminated by '字段分隔符' lines terminated by '行分隔符,一般是\n';主键优化
InnoDB是根据主键顺序存放数据的,这种方式的表被叫做索引组织表(index organized table IOT)。
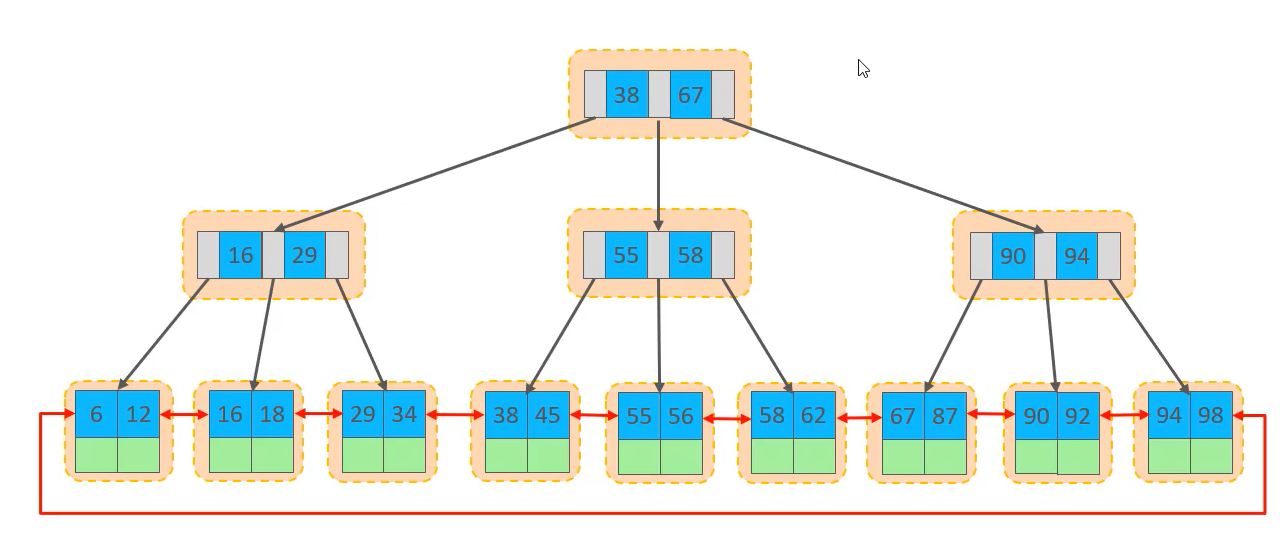
页分裂
页可以为空,也可以一半,也可以满。每个页包含2-N行数据(如果一行数据过大,会行溢出),根据主键排列。
当我们插入一个数据时,如果一个页满了,此时如果不是顺序插入,该数据是在这个页的中间,那么就会发生页分裂现象,也就是B+Tree数据结构的中间元素向上分裂:

页合并
当我们删除记录时,实际上记录并没有被删除,只是记录被标记为删除,并且它的空间可以被其他记录使用。
当删除的记录达到某一个阈值 MERAGE_THRESHOLD(默认为页的50%,在建表和建索引的时候可以设置)之后,InnoDB会开始寻找最靠近的页(前或后),看看是否可以将两个页合并成一个页,来优化空间:

合并之后:

主键设计原则
- 满足业务需求的情况下,尽量短,因为二级索引叶子节点挂的是主键,如果主键很长,二级索引很多,那么会占用很多的磁盘空间,搜索的时候会耗费大量磁盘IO,降低搜索效率。
- 插入数据时尽量选择顺序插入,避免页分裂。
- 不要用uuid和身份证之类的做主键,因为是无序的,没办法做到顺序插入,而且长度也很长。
- 业务操作尽量不要对主键做修改。
order by优化
Using filesort
通过索引或者全表扫描,读取数据,然后在排序缓冲区(sort buffer)中完成排序操作。所有不是通过索引直接返回排序结果的,都叫做FileSort排序。

Using index(必须是覆盖索引)
通过有序索引顺序扫描直接返回有序数据,不需要额外排序,效率高。
如果用字段a和b建立联合索引,然后用a和b排升序或者降序,此时就是Using Index。但是如我们要a降序,b升序,此时就会退化成Using FileSort,此时我们可以建立一个a降序、b升序的联合索引,就可以避免。
注意,必须是覆盖索引的情况下才是Using Index,否则还是Using FileSort。如果不可避免FileSort,大数据量排序的时候,可以增大缓冲区大小:sort_buffer_size(默认256k)。
group by优化(索引)
根据部门id分组结果如下:
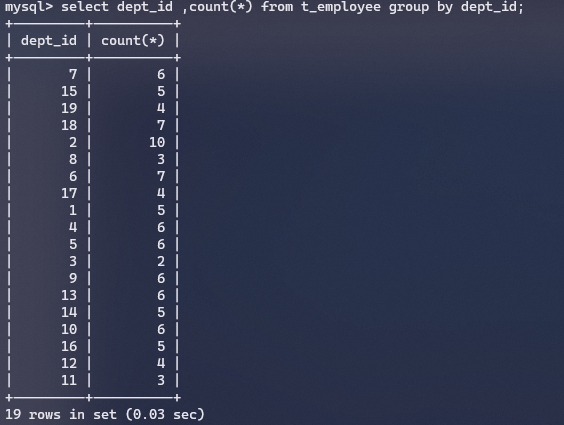
对应的执行计划如下,此时并没有走索引,type是ALL,全表扫描:

建立索引之后,就开始使用索引了,type是index,Extra也是 Using Index:

建立联合索引(专业,年龄,状态):

然后使用第二个字段(age)进行分组,此时会出现Using Index和Using temporary,因为不满足最左前缀法则:

如果使用第一个字段过滤、第二个字段分组,或者前两个字段都用来分组,就不会出现Using temporary,因为符合最左前缀法则:


limit优化(覆盖索引+子查询)
在分页大数据量的时候,获取越靠后的数据,性能越低如 limit 500000,10,此时需要查询5000010条数据,但是仅返回最后十条数据,代价非常大。
当前表的数据量为一千万:
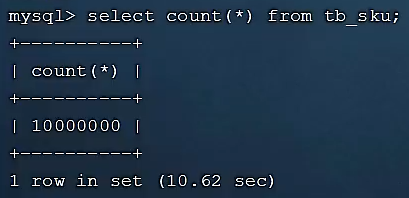
我们查询 limit 900000,10,最后耗时19秒:


官方给出的优化方案是覆盖索引+子查询的方式来优化。
覆盖索引,只查出id:
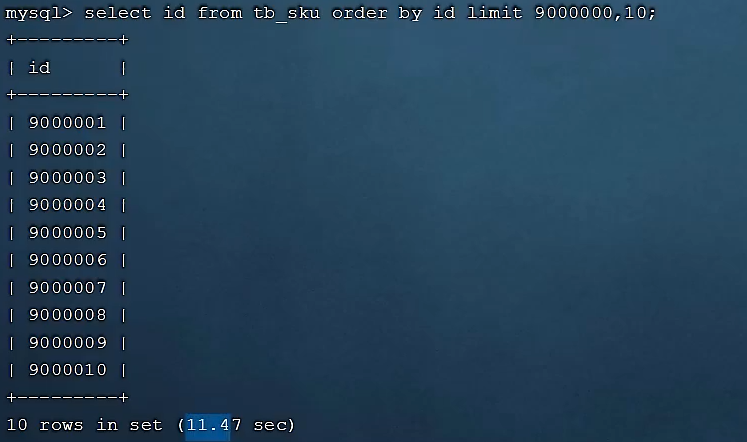
然后通过子查询的方式获取数据,但是版本不支持子查询里面使用limit,所以我们通过连表的方式来实现,最后耗时11秒,优化了8秒时间:


count优化(自己计数)
MyISAM引擎把表的总行数存在磁盘上,因此执行count(*)直接返回,效率很高(前提是不带过滤条件),而InnoDB没有记录,就是直接一行一行的读取计数。
目前也没有对于count特别好的优化方案。我们可以自己计数,借助KV数据库来计数,插入的时候给某一个计数+1,删除的时候-1,这个就比较繁琐。
count在大数据量的时候查询是比较耗时的,这个是由存储引擎决定的。
count是一个聚合函数,他会一行行判断,如果count的参数不是NULL,那么就+1,否则不加,最后返回累计值。
count(*):
InnoDB并不会取值,而是专门做了优化,服务层直接按行进行累加。
count(1):
InnoDB会遍历整张表,但是不取值,返回给服务层的每一行都会放一个1进去( count(0)就放0,count(-1)就放-1 ),然后进行累计,只要不为null都会累加。
count(主键):
InnoDB会遍历整张表,把id取出来返回给服务层,然后服务层开始计数。
count(字段):
和主键一样,不一样的是如果没有not null约束,服务层会对null进行判断。
所以性能的顺序是:count(*) = count(1) > count(主键) > count(字段)。
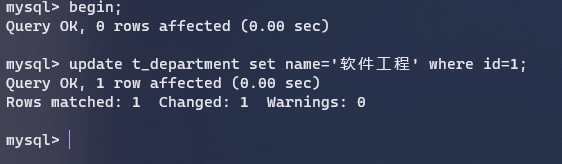
update优化(避免行锁升级成表锁)
默认是行锁,当我们开始事务时,对修改的数据会加上行锁,事务结束之后才会放锁 :
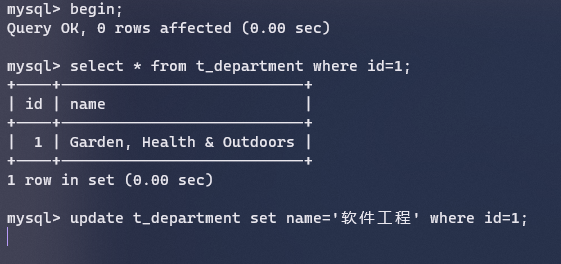
此时如果我们用另外一个事务去修改这行数据,就会被阻塞,知道上一个事务放锁,该事务才能继续修改:
但是如果过滤条件没有建立索引,那就是表锁,如下我们通过name(没有索引)来过滤:
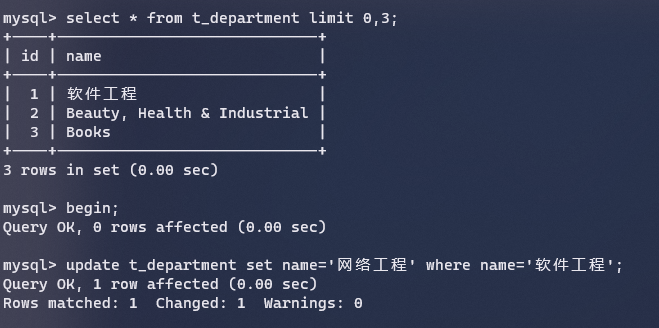
然后我们在另外一个事务里面修改name为Books的数据,虽然不是同一行数据,但是也会阻塞,因为此时加的是表锁,不是行锁:

此时已经卡住了,需要等待上一个事务放锁,如果一直不放锁,则会超时结束。
我们在更新字段的时候,行锁是针对于索引加的锁,不是针对记录,所以一定要根据索引字段进行更新!
锁
概述
锁是计算机协调多个线程或者进程并发访问的某一资源的机制。在数据库中,除了传统的计算机资源的争用以外,数据也是一种供多个用户共享的资源。
按照粒度划分,可以分为:
- 全局锁:锁定数据库中的所有表
- 表级锁:每次操作锁住整张表
- 行级锁:每次操作锁住对应行
全局锁
对整个数据库实例加锁,加锁之后只处于只读状态,其他语句将被阻塞。典型的使用场景是全库的逻辑备份,对所有表锁定,获取一致性的视图,保证数据一致性和完整性。
# 对当前数据库加上全局锁
FLUSH TABLES WITH READ LOCK;# 备份工具
mysqldump -uroot -p1234 数据库名 > 文件.sql# 释放全局锁
UNLOCK TABLES;全局锁是一个很重的操作:
- 加锁期间不能修改,业务基本上停摆。
- 如果是从库备份,那么从库不能及时同步主库的二进制日志(binlog),导致主从延迟。
InnoDB中,可以备份时加上 --single-transaction 来完成不加锁的备份,底层是通过MVCC快照读来实现的:
# 备份工具
mysqldump --single-transaction -uroot -p1234 数据库名 > 文件.sql表级锁
每次操作锁住整张表,粒度大,极易发生锁冲突,并发度最低。
表锁分为三类:
- 表锁
- 元数据锁(meta data lock,MDL)
- 意向锁
表锁
分为两类:表共享读锁、表独占写锁。
# 加锁
LOCK TABLES 表名 READ / WRITE
# 放锁
UNLOCK TABLES / 客户端断开连接读锁(共享锁):所有连接只能读,不能写,直到放锁或者超时。
写锁(排他锁):当前连接可读可写,其他连接全部阻塞。
元数据锁
MDL锁MySQL服务层实现的表级锁,用来保护表结构,是系统自动控制的,不需要显示使用。在访问一张表的时候自动加上。MDL锁是为了维护表元数据的数据一致性,在表上面有活动事务的时候,不可以对元数据进行写入操作。为了避免DML和DDL冲突,保证缺血的正确性。
当对一张表进行增删改啥的时候,自动加上DML读锁(共享锁),当对表结构进行修改的时候,加DML写锁(排他锁)。

查看元数据锁:
select
obiect_type,obiect_schema,obiect_name,lock_type,lock_duration
from performance_schema.metadata_locks;metadata_locks表记录了当前有哪些元数据锁。
意向锁
如果线程A添加了行锁,然后线程B此时再添加表锁,锁就冲突了,所以线程B会逐行检查有没有行锁以及行锁的类型,来判断到底能不能加锁成功,这个性能就极低。
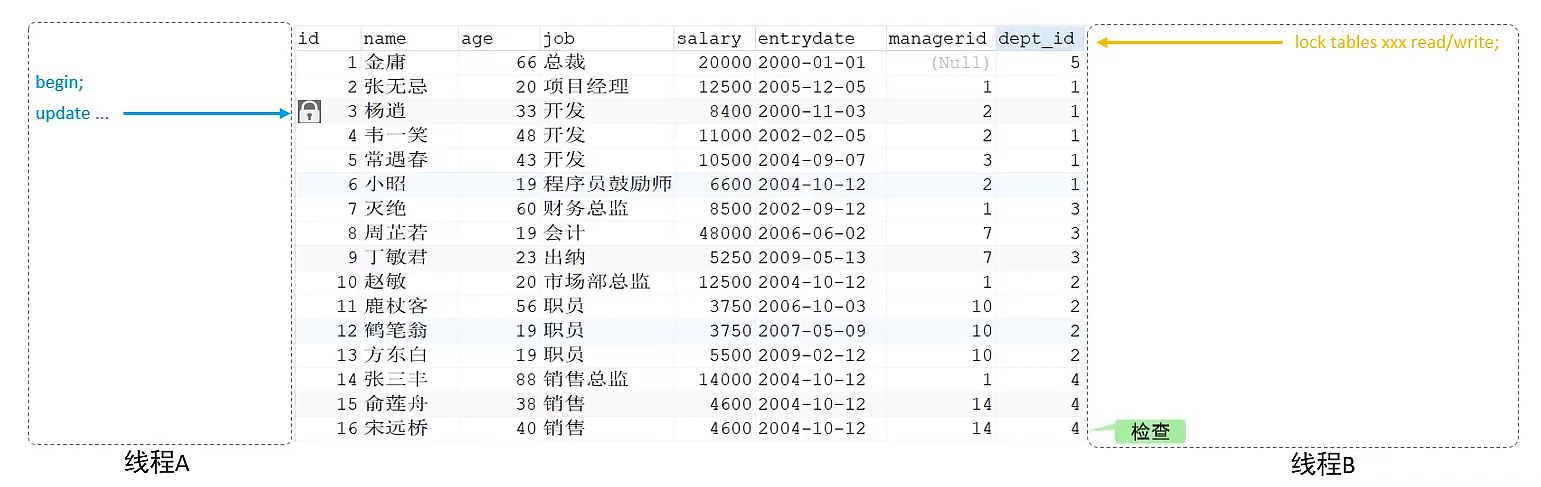
为了避免DML时,行锁和表锁的冲突,InnoDB引入了意向锁,使得表锁不用逐行检查数据是否加锁。
引入意向锁之后,线程A添加行锁的时候,同时也会给表加上意向锁,线程B加表锁的时候,就会去判断意向锁,如果兼容,就可以加上表锁,否则阻塞。
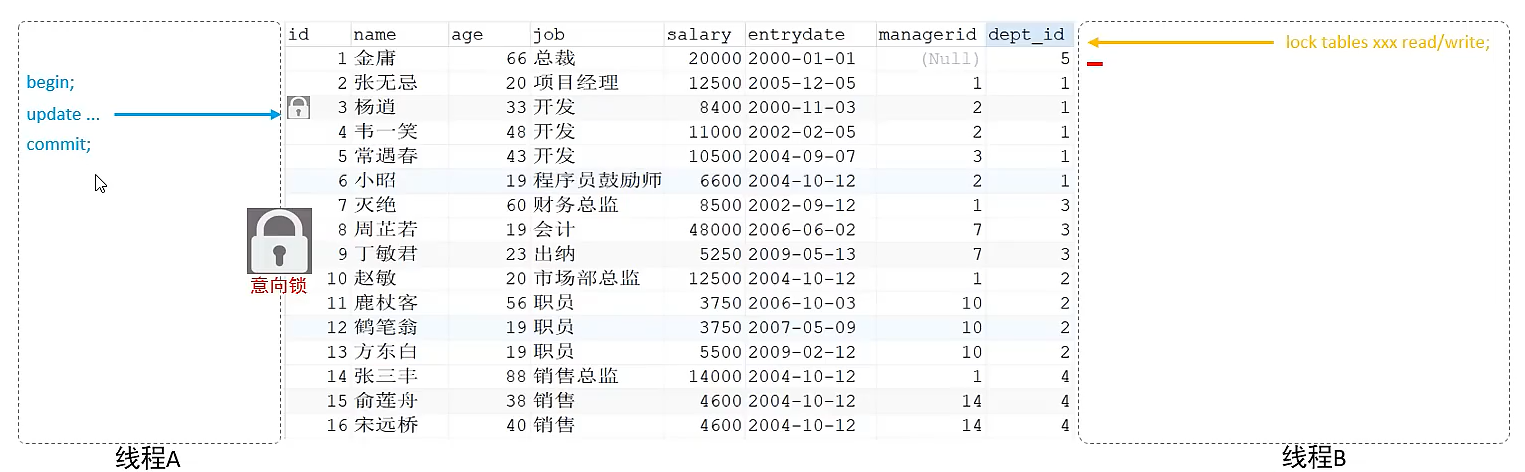
意向锁分为:
意向共享锁(IS):由语句select ... lock in share mode 添加。和表锁共享锁兼容,与表锁排他锁互斥。
意向排他锁(IX):由insert、update、delete、select ... for update 添加。与表锁都互斥,意向锁之间不会互斥。
查看意向锁加锁情况:
select
obiect_schema,obiect_name,index_name,lock_type,lock_mode,lock_data from performance_schema.data_locks;行级锁
每次操作时锁住对应的数据行,颗粒度最小,发生所冲突的概率最低,并发度最高,应用在InnoDB存储引擎中。
InnoDB数据是由索引组织的,行锁是通过对索引上的索引项进行加锁来实现,而不是对记录来实现。
行锁主要分为三类:
- 行锁(Record Lock):锁定单个行记录的锁,防止其他事务对次进行update和delete。在RC、RR隔离级别下都支持。
- 间隙锁(Gap Lock):锁定索引记录间隙(不含该记录),确保索引记录间隙不变,防止其他事务在这个间隙进行insert,产生幻读。在RR隔离级别下都支持。
- 临键锁(Next-Key-Lock):行锁和间隙锁的组合,同时锁住数据和数据前面的间隙。在RR隔离级别下都支持。
行锁(Record Lock)
InnoDB提供一下两种行锁:
- 共享锁(S):允许所有事务去读取,但阻止其他事务获得相同数据集的排他锁。
- 排他锁(X):允许获取排他锁的事务更新数据,阻止其他事务获得相同数据集的共享锁和排他锁。
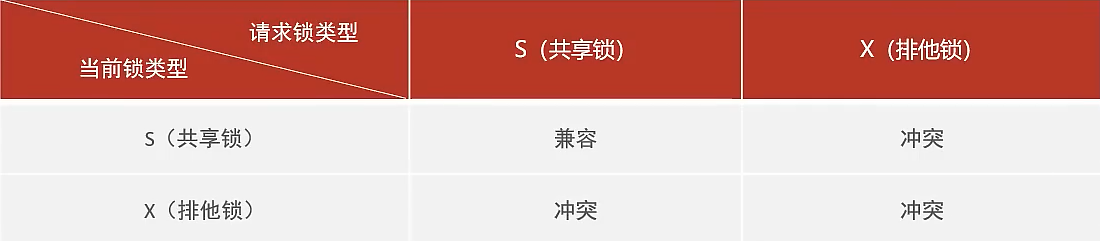
加锁:

概括一下就是,增删改自动加排他锁,select默认没锁,加上lock in share mode为共享锁,加上for update 为排他锁。
默认情况下,InnoDB在RR隔离级别下,使用next-key锁进行搜索和索引扫描,防止幻读。
- 针对唯一索引进行检索时,对已存在的记录进行等值匹配时,会自动优化为行锁。
- InnoDB的行锁时针对于索引加锁,不通过索引条件检索数据,那么就会升级为表锁。
查看行锁的加锁情况:
select obiect_schema,obiect_name,index_name,lock_type,lock_mode,lock_data from performance_schema.data_locks;间隙锁(Gap Lock)& 临键锁(Next-Key-Lock)
默认情况下,InnoDB在RR隔离级别下,使用next-key锁进行搜索和索引扫描,防止幻读。
间隙锁唯一目的是防止其他事务插入间隙。间隙锁可以共存,一个事务采用的间隙锁不会阻止另一个事务,在同一个间隙上采用间隙锁。
唯一索引上的等值查询
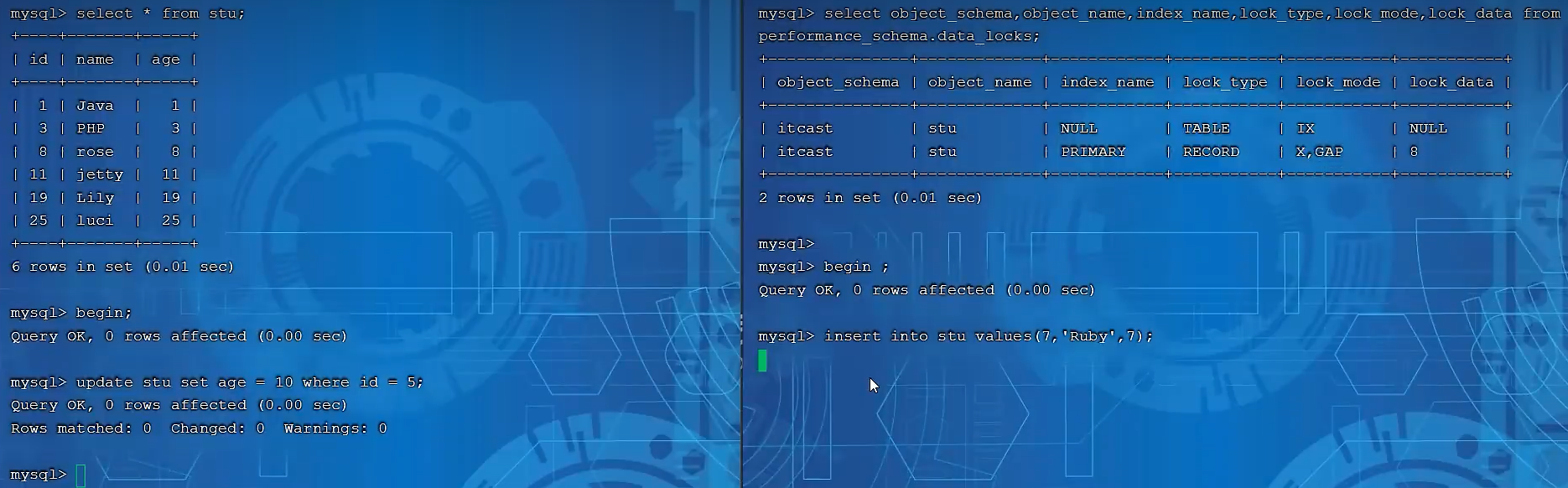
唯一索引上的等值查询,给不存在的记录加锁时,优化为间隙锁。如图,两个窗口都开启事务,左边窗口更新id=5的数据(不存在的数据),右边窗口可以看到查看行锁的加锁情况,此时已经有了一个GAP锁,锁住的是(3,8)之间的间隙(因为5是在这个间隙里)。
此时右边窗口如果插入一条id为7的数据,是会阻塞的,因为加了间隙锁。
普通索引上的等值查询
普通索引上的等值查询,向右遍历时最后一个值不满足查询需求时,next-key退化为间隙锁。
如下图,如果不是唯一索引, 假如我们对18进行查询并加上共享锁,但是在这之后,其他事务可能会在18之前插入一个18,也可能在18之后插入一个18。所以,我们会把18加上一个共享锁,18之前的间隙(16,18)加上一个间隙锁,29之前的间隙(18,29)加上一个间隙锁,所以最终,锁的范围是(16,29)。

观察下面这个例子,我们给id为3的记录加上了共享锁,我们查看右边的加锁状态:
- 第二行是给age为3、id为3的记录加上间隙锁,也就是(1,3)的部分。
- 第三行是我们手动加上的共享锁。
- 第四行是给age为7、id为7的记录加上间隙锁,也就是(3,7)的部分。
所以,最终锁住的范围是:(1,7) 。

唯一索引上的范围查询
唯一索引上的范围查询,会访问到不满足条件的第一个值为止。
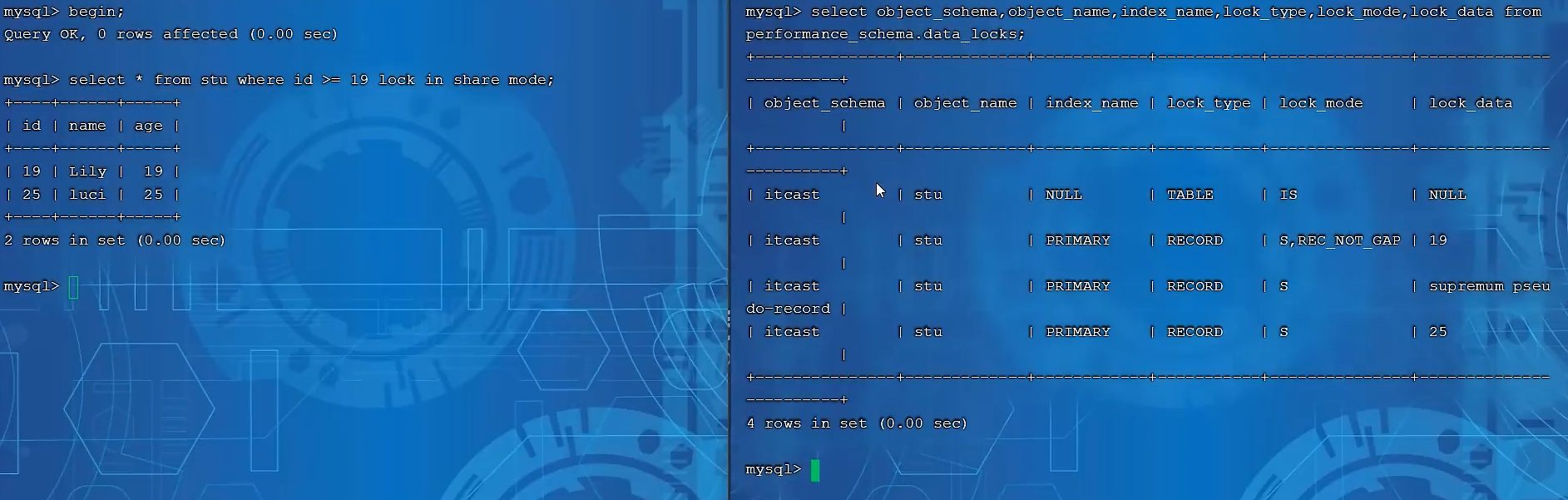
观察下面的例子,我们查询>=19的记录,并手动加上共享锁,然后查看加锁状态:
- 第二行,对19加了一个共享锁。
- 第四行,对25加上了一个临键锁,也就是 (19,25] 的部分。
- 第三行,对+无穷加上了一个临键锁,也就是 (25,+∞) 的部分。
所以最终锁住的范围是:[19,+∞ ) 。
事务原理
事务时一组操作的集合,不可分割的工作单位,事务的四大特性:ACID
特性
- 原子性(A):不可分割,要么全部成功,要么全部失败
- 一致性(C):事务完成,所有数据都保持一致
- 隔离性(I):根据隔离机制,保证事务不受外部并发操作下独立运行
- 持久性(D):一旦提交或者回滚,它对数据库的改变就是永久的
ACD是由redo log和undo log来保证的,I是由锁机制和MVCC来保证的。
持久性(redo log来保证)
持久性是有redo log来保证的。当缓冲区数据更改时,会把修改的数据保存到redo log buffer中,在事务提交的时候,会把redo log buffer刷到redo log文件里。
如果后面在刷脏的时候出错了,就可以通过redo log来恢复,因为redo log记录了当次数据的变化。
如果刷脏成功,那么redo log里的记录就没有意义了,所以每隔一段时间就会去清理redo log日志。
为什么每次事务提交都把redo log刷新到磁盘,而不是直接刷新数据?
可以直接刷新数据,但是存在严重的性能问题。因为一个事务通常会操作很多条记录,而这些记录所在的数据页都是随机的,会造成大量的随机磁盘IO。但是我们刷日志文件的话,日志文件都是顺序追加的,所以速度很快。
如果日志刷盘的时候失败了怎么办?
原子性(undo log来保证)
回滚日志,用来记录数据被修改前的信息,作用包含两个:提供回滚的MVCC,在多版本并发控制的时候,可以依据undo log来找到记录的历史版本。
redo log记录的是物理记录,即记录真实的数据,而undo log是逻辑记录,记录的是每一步的反向操作,可以认为执行delete的时候,undo log会有一条相反的insert操作,执行update操作的时候,会有一条相反的update操作。当事务回滚时,就会执行对应的反向操作,恢复成之前的数据,这样就会保证事务的原子性。
undo log销毁:一旦事务提交或者回滚,那么这份undo log也就不需要了,但是它不会立即去删除,还会去检查MVCC会不会用到该日志。
undo log存储:采用段的方式进行管理和存储,存放在rollback segment回滚段中,里面包含1024个undo log segment。
隔离性(MVCC和锁)
前置概念
当前读
读取的是记录的最新版本,读取的时候保证其他并发事务不能修改当前记录,所以会对记录进行枷锁。如:
SELECT ... LOCK IN SHARE MODE # 共享锁
SELECT ... FOR UPDATE、 INSERT、 DELETE # 排他锁这些锁都是一种当前读。
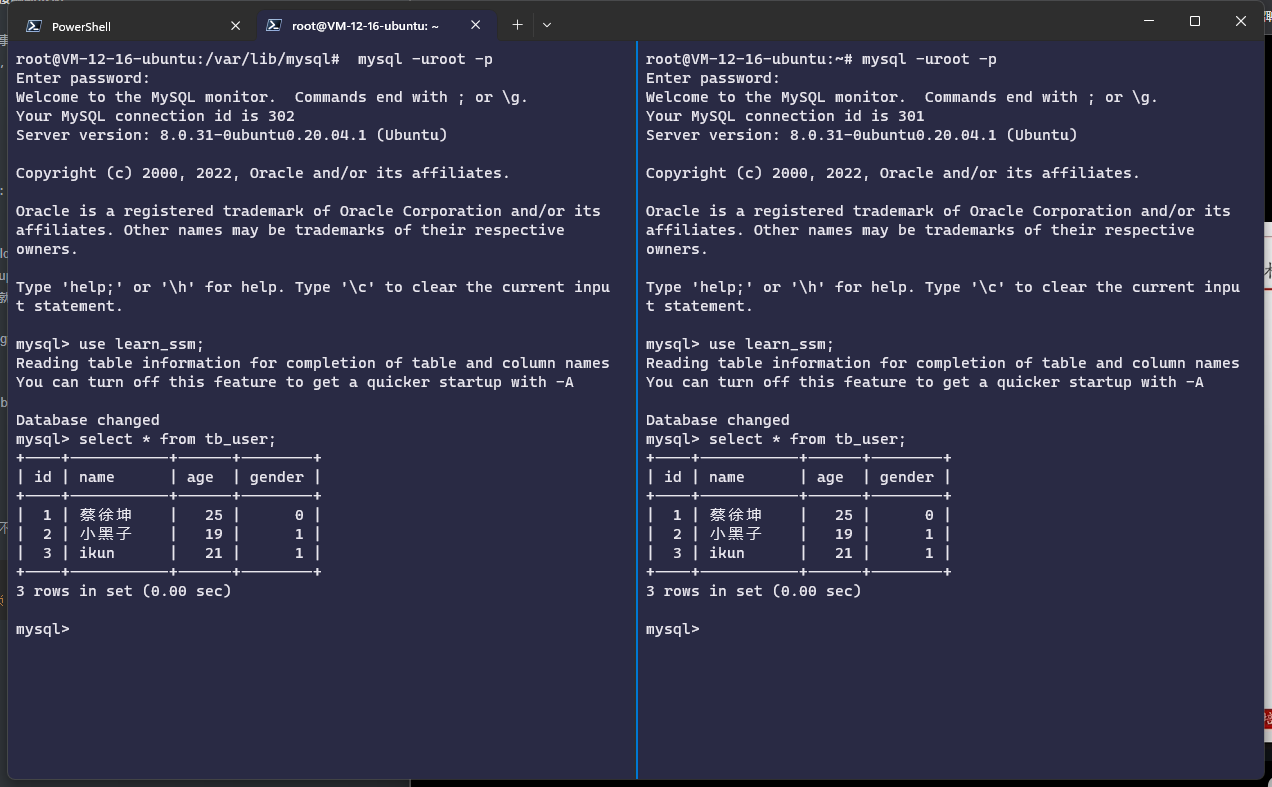
下面演示一下当前读:
首先我们打开两个MySQL连接,选择了learn_ssm数据库,展示了tb_user表的数据
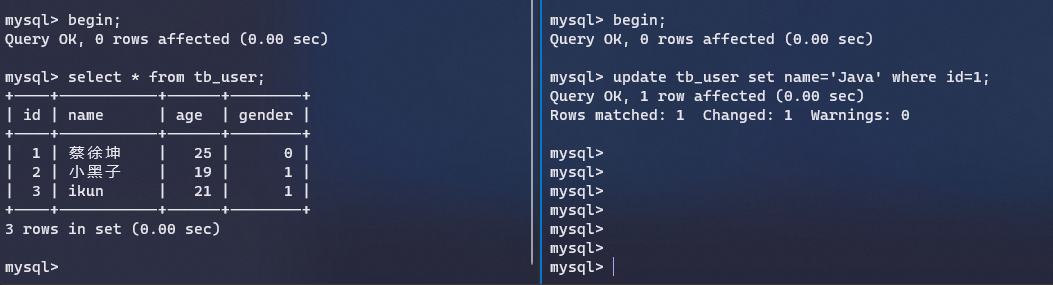
然后我们使用begin分别开启两个事务

在第二个连接里面修改一条记录,这个时候事务还没有提交,我们在第一个连接里面查看,发现读取不到修改
当我们提交事务之后,发现第一个连接还是读取不到修改
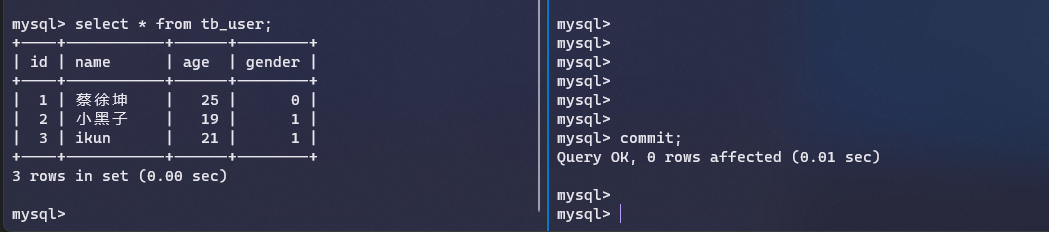
这是因为InnoDB默认的隔离级别是可重复读,所以不会感知到其他事务的修改,这个时候我们在第一个连接里面加上当前读的锁,就可以得到最新的数据
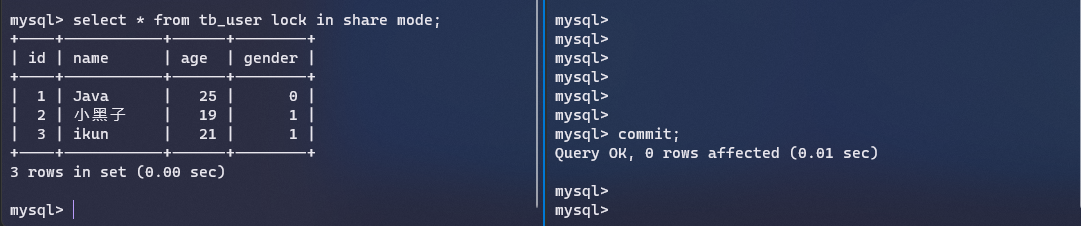
这个就是当前读的作用,用来获取记录的最新版本。
快照读
简单的不加锁的select语句就是快照读,读取的是记录数据的可见版本,有可能是历史数据,不加锁所以它是非阻塞的。
- Read Committed:每一次select都会产生一个快照读
- Repeatable Read:开启事务后第一个select语句才是快照读,后面读的都是前面产生的快照
- Serializable:快照读会退化成当前读,每一次读都会加锁
MVCC
全称 Multi-Version-Concurrency-Control,多版本并发控制。维护一个数据的多个版本,使得读写操作没有冲突,快照读给MVCC提供了非阻塞读功能。当我们在快照读的时候,就要通过MVCC来获取记录的历史版本。MVCC的实现还依赖于数据记录里的三个隐藏字段、undo日志和readView。
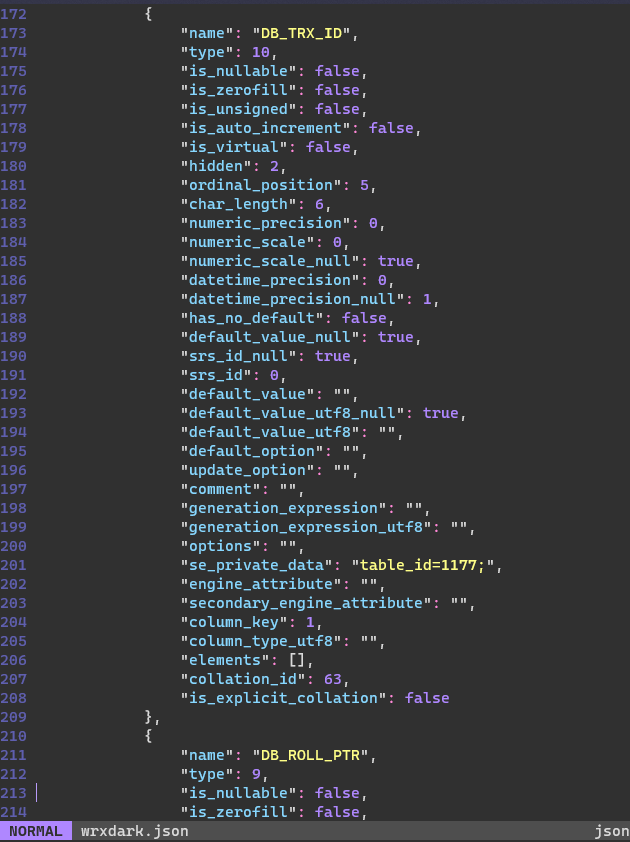
隐藏字段
| 隐藏字段 | 作用 |
|---|---|
| DB_TRX_ID | 最近一次修改或插入该记录的事务的ID |
| DB_ROLL_PTR | 回滚指针,指向这条记录的上一个版本,配合undo日志一起使用 |
| DB_ROW_ID | 隐藏主键,如果这张表没有人为设置主键,那么就会生成这个字段作为记录的主键 |
我们可以使用ibd2sdi命令查看ibd文件信息,在这里我们可以看到这些隐藏字段:
首先进入数据库目录,然后输入 ibd2sdi tb_user.ibd 查看文件信息
在columns下面我们可以找到最近事务ID和回滚指针:
undo日志
当insert的时候,产生的undo日志只在回滚时需要,所以在事务提交后,可以被立即删除。
而update、delete的时候,产生的undo日志在回滚和快照读的时候都需要,不会被立即删除。
undo日志版本链
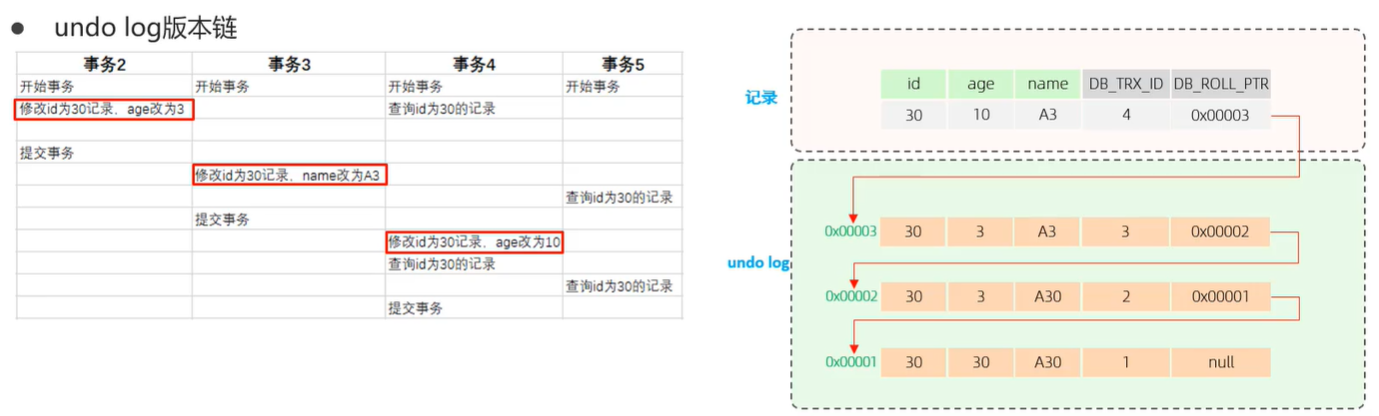
在记录未被修改之前,回滚指针指向null。当我们在事务2里面对记录进行修改,InnnoDB会在undo日志里面保存修改之前的版本,然后用在记录的新版本里面,用回滚指针指向老版本记录的地址,事务id为修改记录的事务的id。
后面的事务3和4的修改也是同样的操作,这样一来我们就得到了一条链表,链表头节点为记录的最新版本,链表尾节点为记录的最老版本,我们可以通过这样一条链表进行记录的回滚操作。
readview
读视图是快照读的时候,MVCC提取数据的依据,记录和维护当前未提交的事务id,包含如下字段:
| 字段 | 含义 |
|---|---|
| m_ids | 未提交事务id集合 |
| min_trx_id | 最小未提交事务id |
| max_trx_id | 预分配事务id,最大未提交事务id+1(因为事务id是自增的) |
| creator_trx_id | readview创建者的事务id,也就是当前查询事务的id |
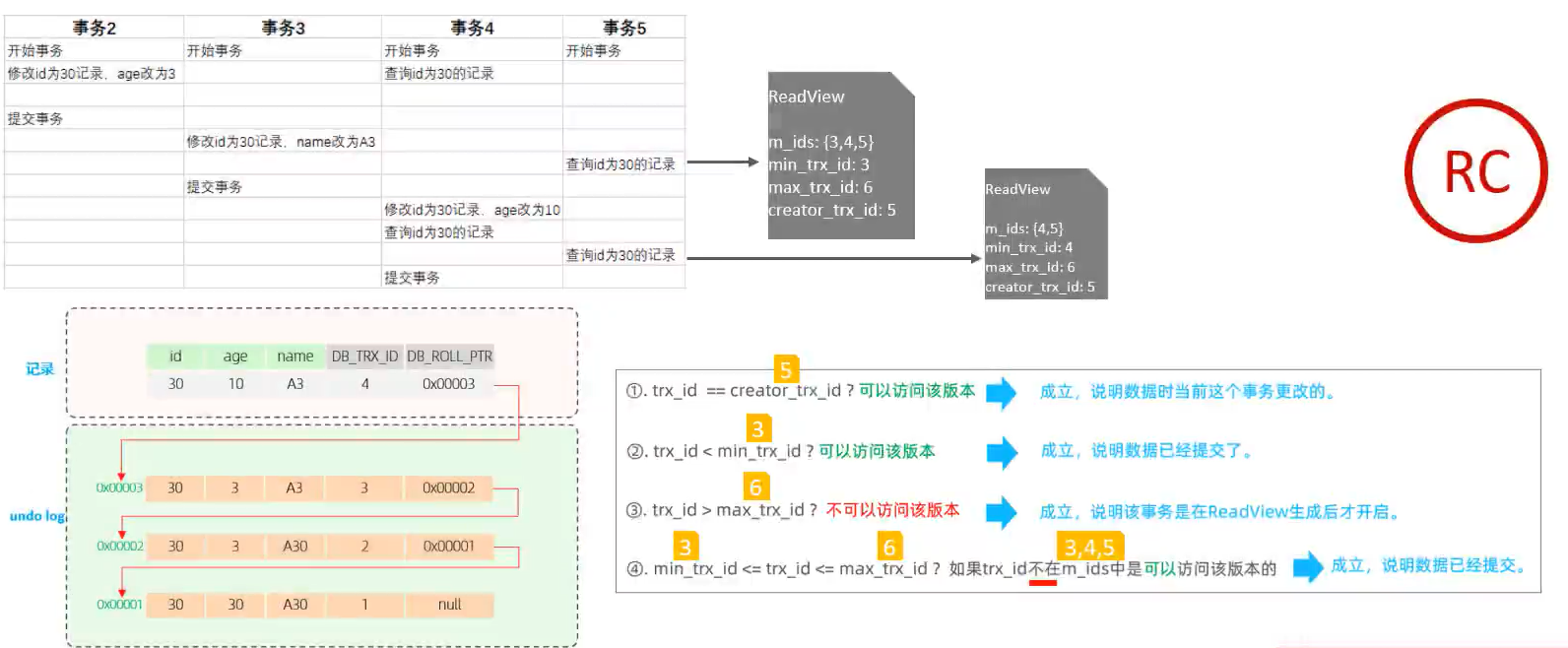
快照读是使用记录的事务id字段去读取的,具体读取规则如下:
当前记录的事务id等于creator_trx_id,也就是说这条记录是我们自己修改的,那么就可以读取。
否则,我们就找最近已提交的事务,也就是不超过max_rtx_id且已经提交了的事务(小于min_trx_id的事务,或者在min和max之间但是不在m_ids内的事务),就是我们要找的那条记录。
如果上述条件都不符合,那么我们就根据undo版本链表回滚记录,直到找到一个符合条件的记录。
因为是在undo日志版本链的记录是从新到旧的,所以我们找到的一定是提交的事务里,最新的那条记录。
不同隔离级别,生成readview的时机:
READ COMMITTED:每次查询都会生成,所以该隔离级别的每次查询都是快照读。
REPEATABLE READ:只在第一次查询的时候生成,后面的查询都是复用第一次,也是因为这个原因,保证了重复读。
下图是在 READ COMMITTED 隔离级别下的情况:
Checkpoint技术
如果在刷脏的时候宕机,那么数据就不能恢复了,为了避免这个问题,当前事务数据库都采用了Write Ahead Log 策略,即当事务提交时先写重做日志,再修改页,宕机之后就可以通过重做日志来恢复。
Checkpoint目的是解决以下几个问题:
- 缩短数据库恢复时间
- 缓存池不够用时,开始刷脏
- 重做日志不可用时,开始刷脏
当数据库宕机时,不需要重做所有日志,因为Checkpoint之前的页已经刷回了磁盘,只需要对Checkpoint之后的重做日志进行恢复,大大缩短了恢复时间。
当LRU算法淘汰的页是脏页时,需要强制执行Checkpoint刷脏。
重做日志的设计是循环使用的,被重用都是不需要的部分,因此可以覆盖使用,若此时重做日志还需要使用,就必须强行产生Checkpoint刷脏。
InnoDB有两种Checkpoint:
- Sharp Checkpoint:将所有脏页刷回磁盘,发生在数据库关闭时。
- Fuzzy Checkpoint:只刷新部分脏页而不是所有,发生在数据库运行时。
Fuzzy Checkpoint发生的几种情况:
- Master Thread
- FLUSH_LRU_LIST Checkpoint:保证LRU列表有100个空闲页,没有就从尾部移除,要是有脏页就进行Chekpoint。
- Async/Sync Flush Checkpoint:重做日志不可用的情况,为了保证重做日志循环使用的可用性。
- Dirty Page too much Checkpoint:脏页太多,当脏页数量占据75%时强制进行Checkpoint,刷新一部分脏页到磁盘。
MySQL主从复制

从库会有两类线程用于同步工作:
- IOThread:从主库拉取binlog日志存入自身的中继日志relaylog
- SQLhread:执行中relaylog中的命令,将数据释放到数据库
分库分表
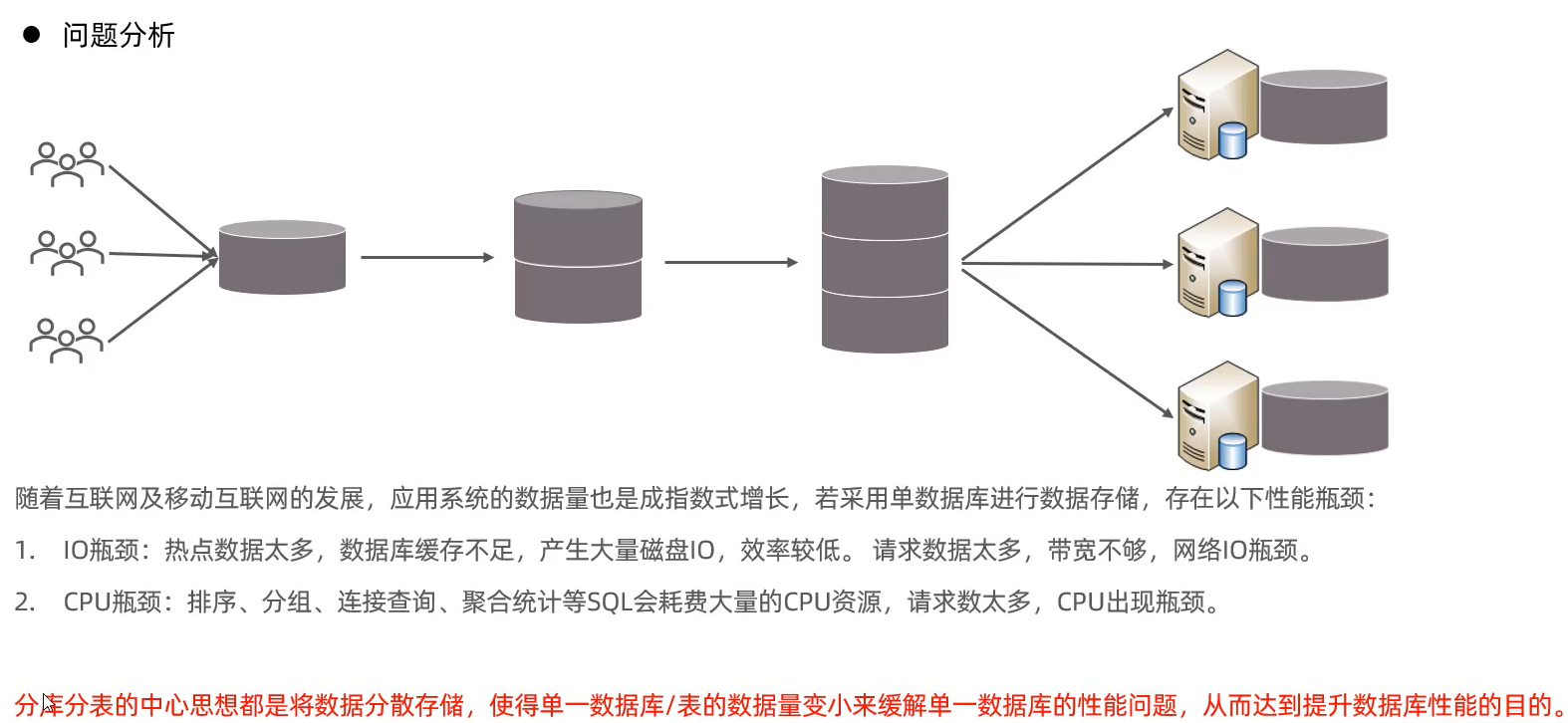
单数据库存在的问题
拆分策略
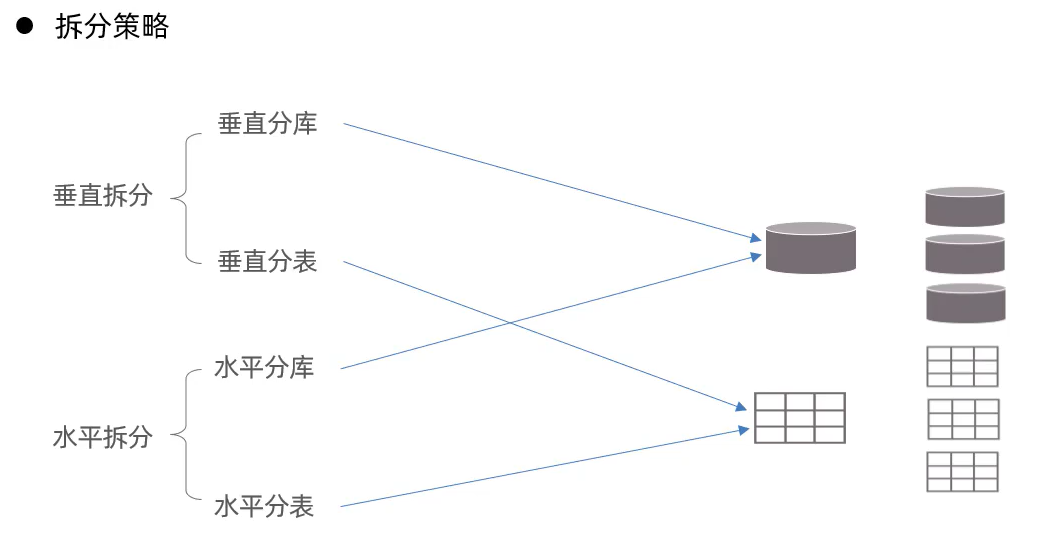
垂直拆分
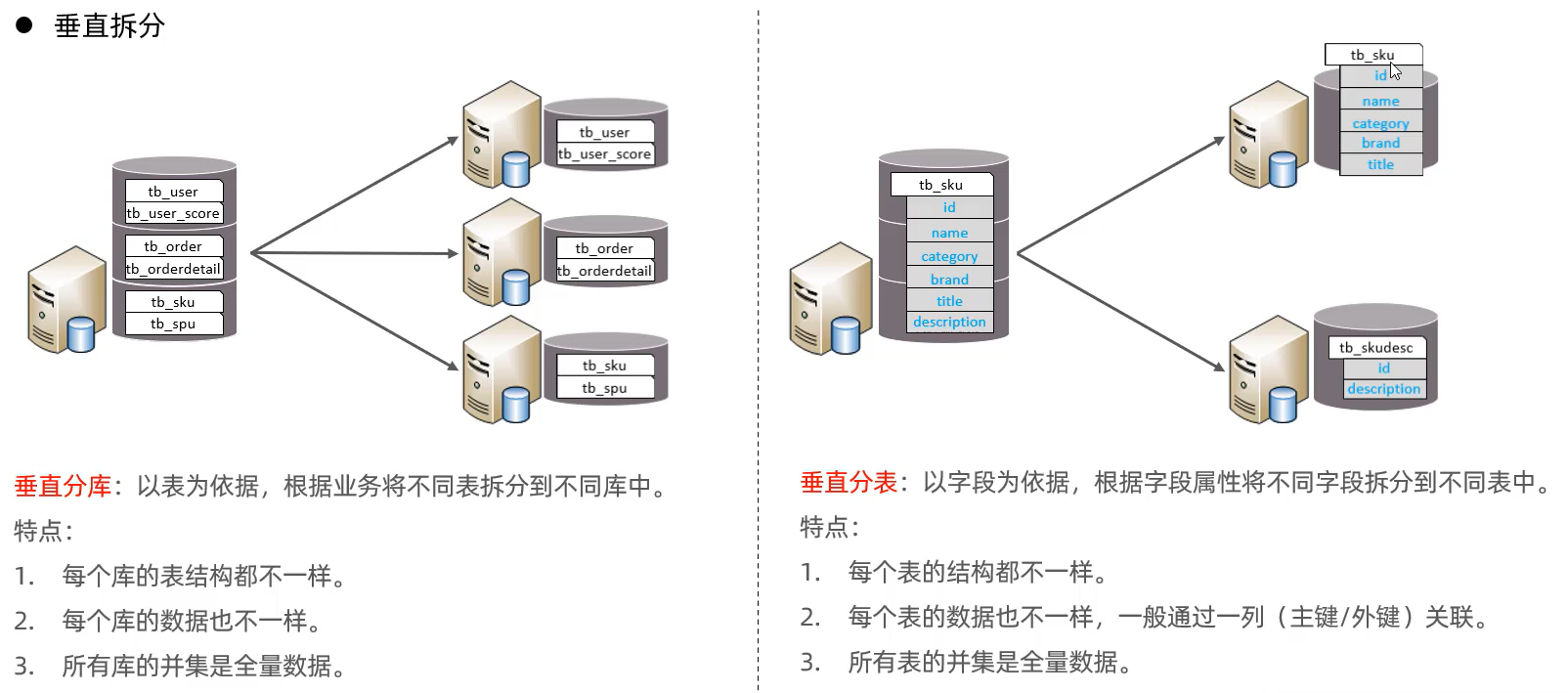
水平拆分
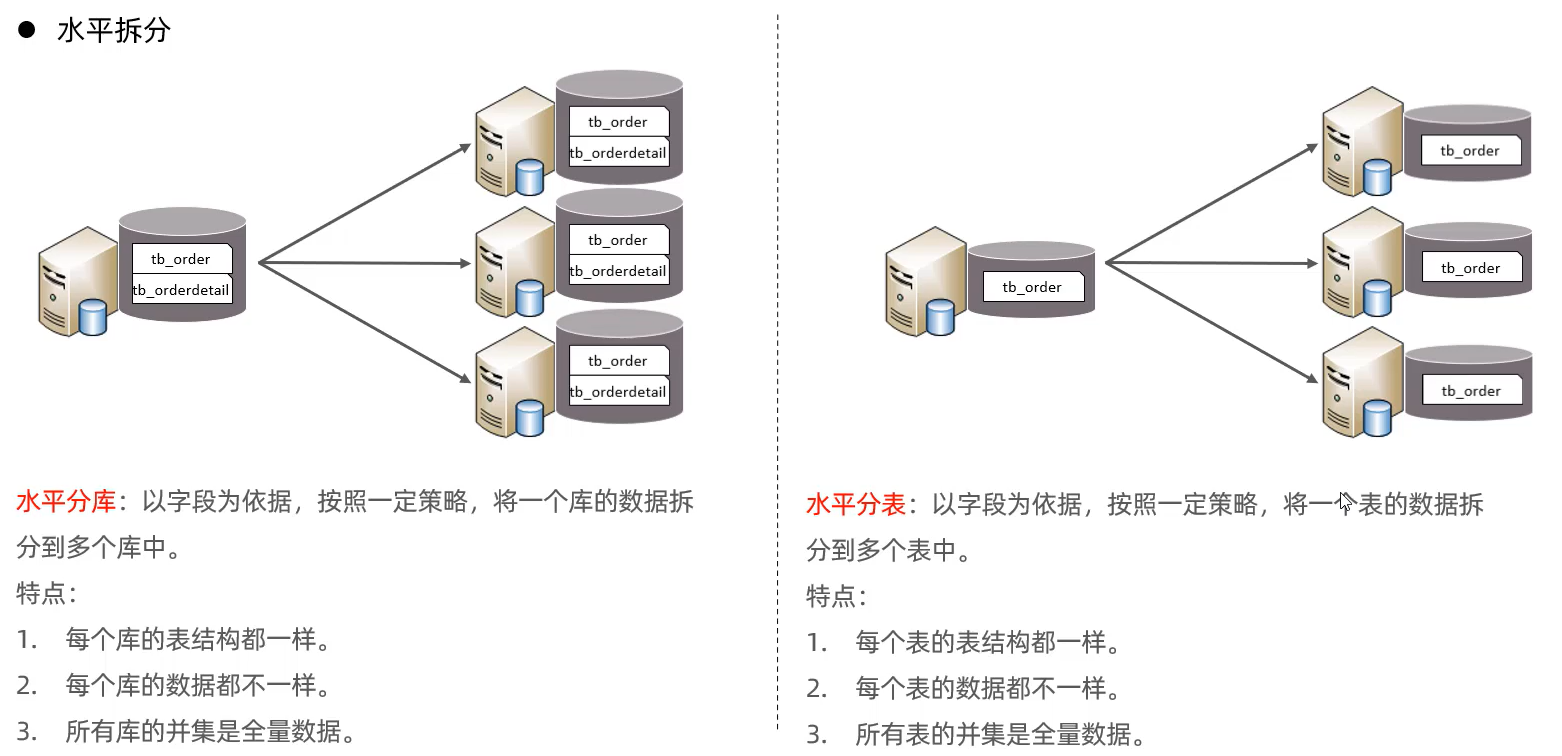
实现技术
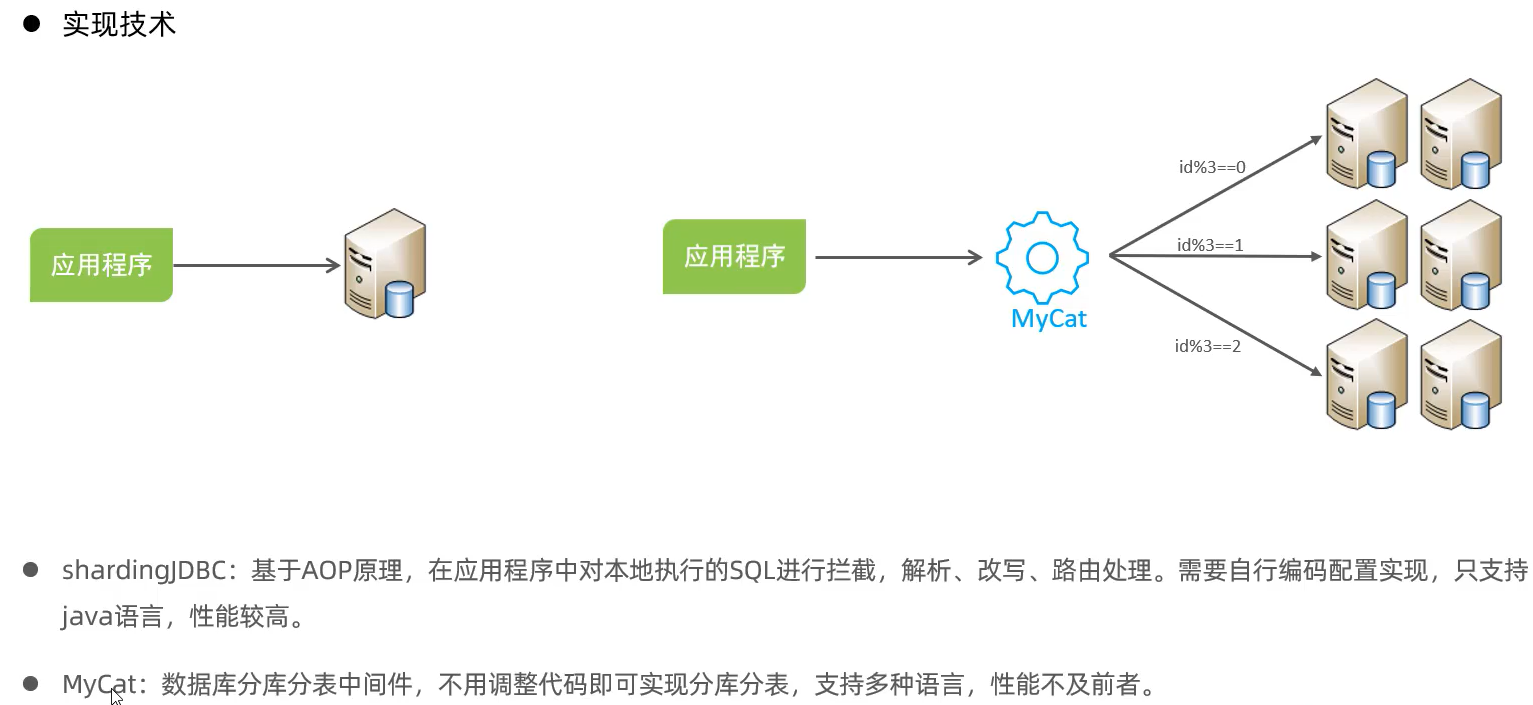
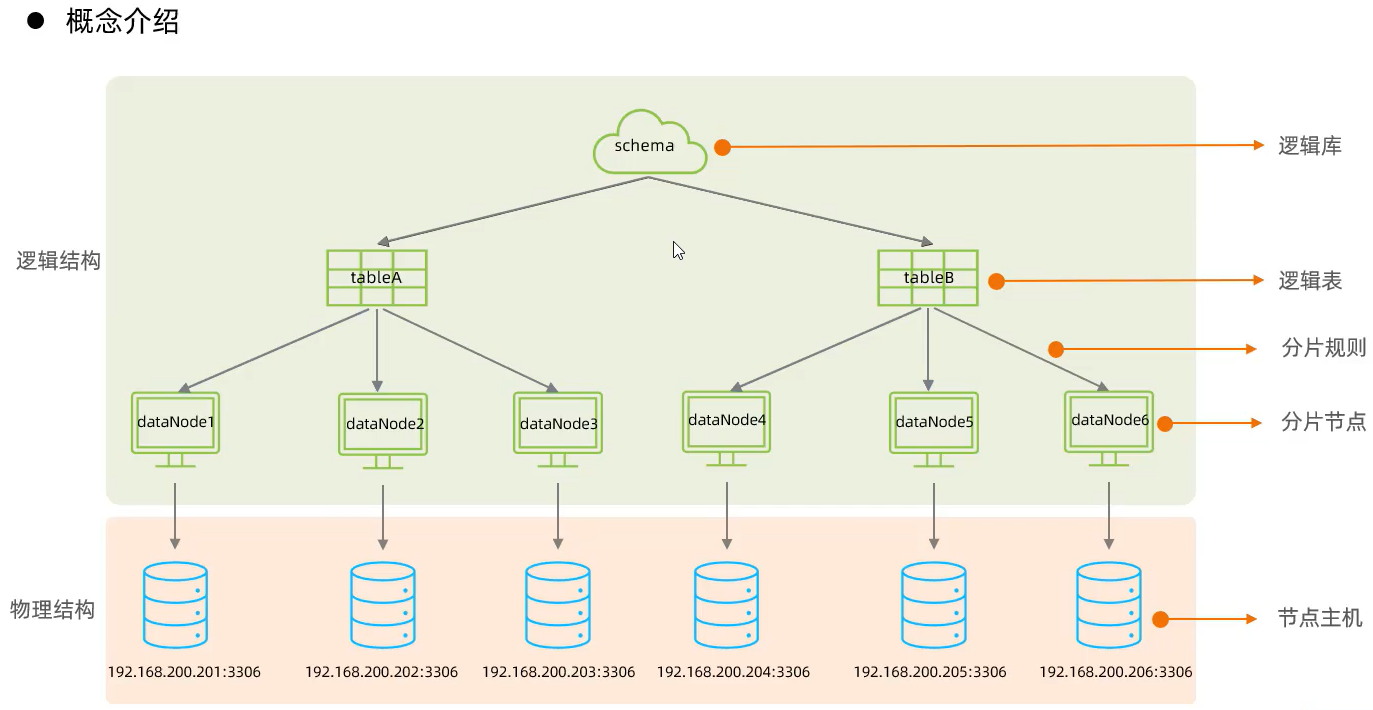
MyCat
介绍
MyCat基于MySQL的网络通讯协议,所以开发者连接MyCat就和连接MySQL一样,没有任何区别。

配置
逻辑库和表(schema.xml)
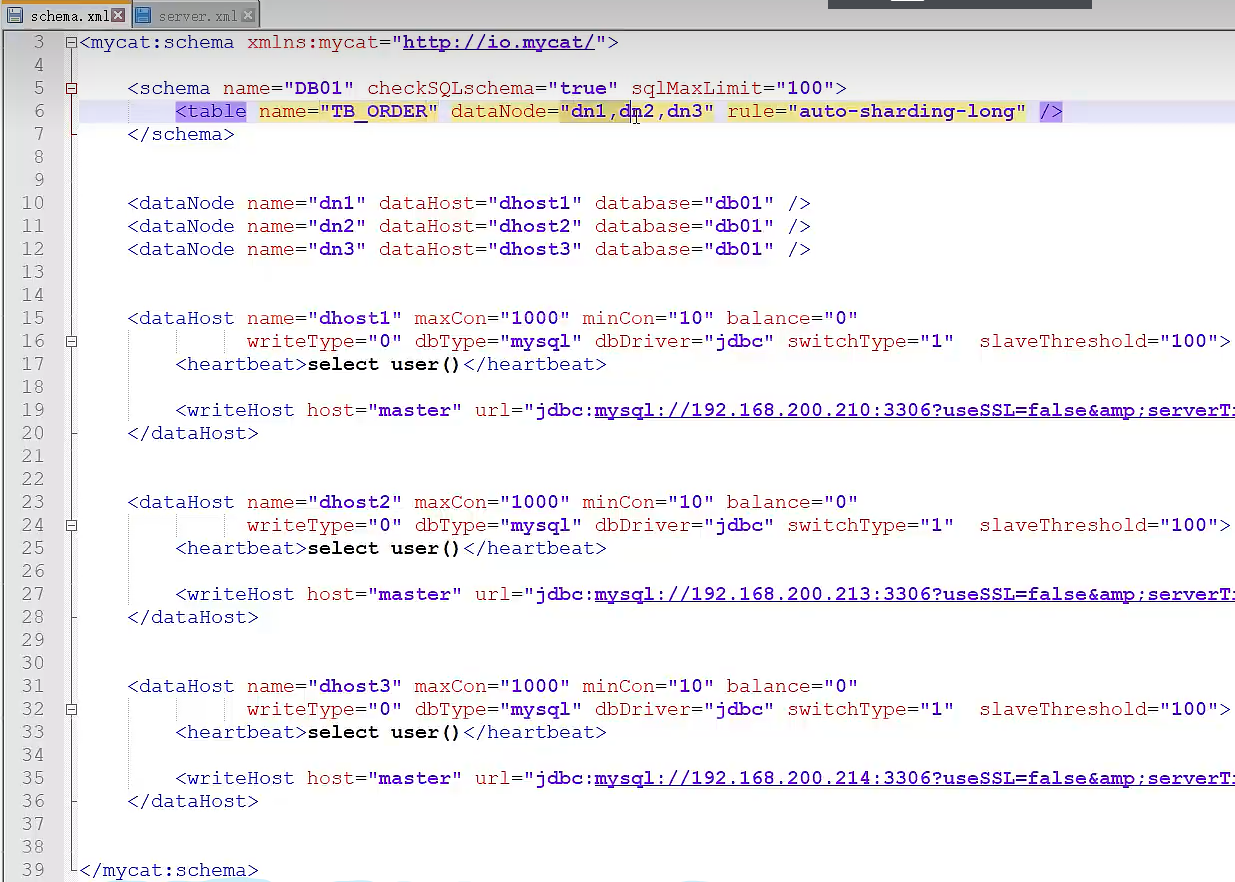
schema 标签用于定义 MvCat实例中的逻库,一个MyCat实例中,可以有多个逻辑库,可以通过 schema 标签来划分不同的逻辑库。 MyCat中的逻辑库的概念,等同于MySL中的database概念,需要操作某个逻辑库下的表时,也需要切换逻辑库(use xxx)。
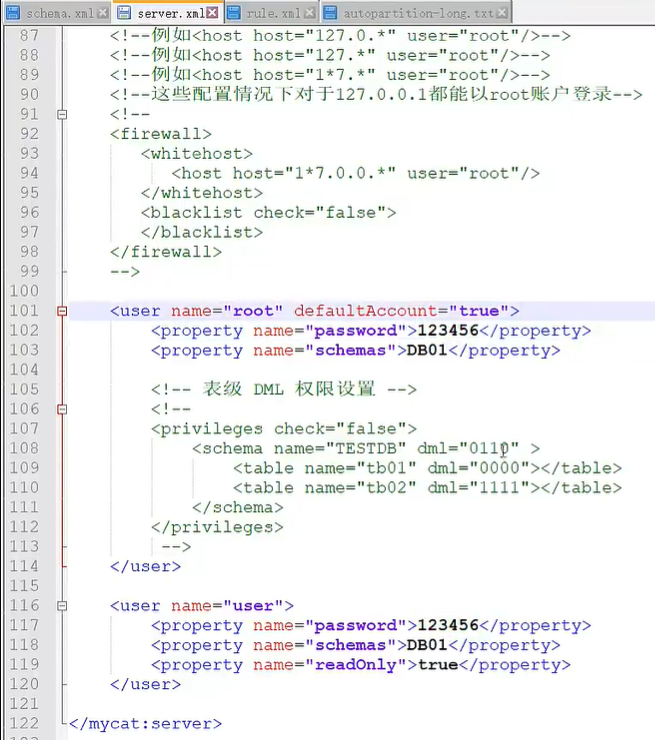
连接服务配置(server.xml)

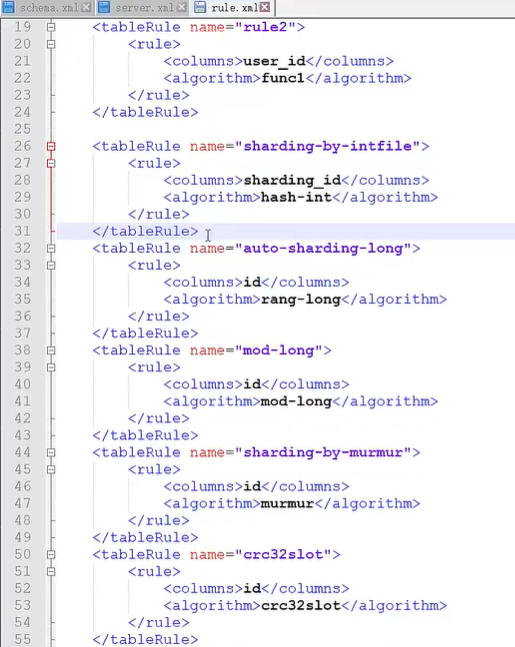
分片规则(rule.xml)
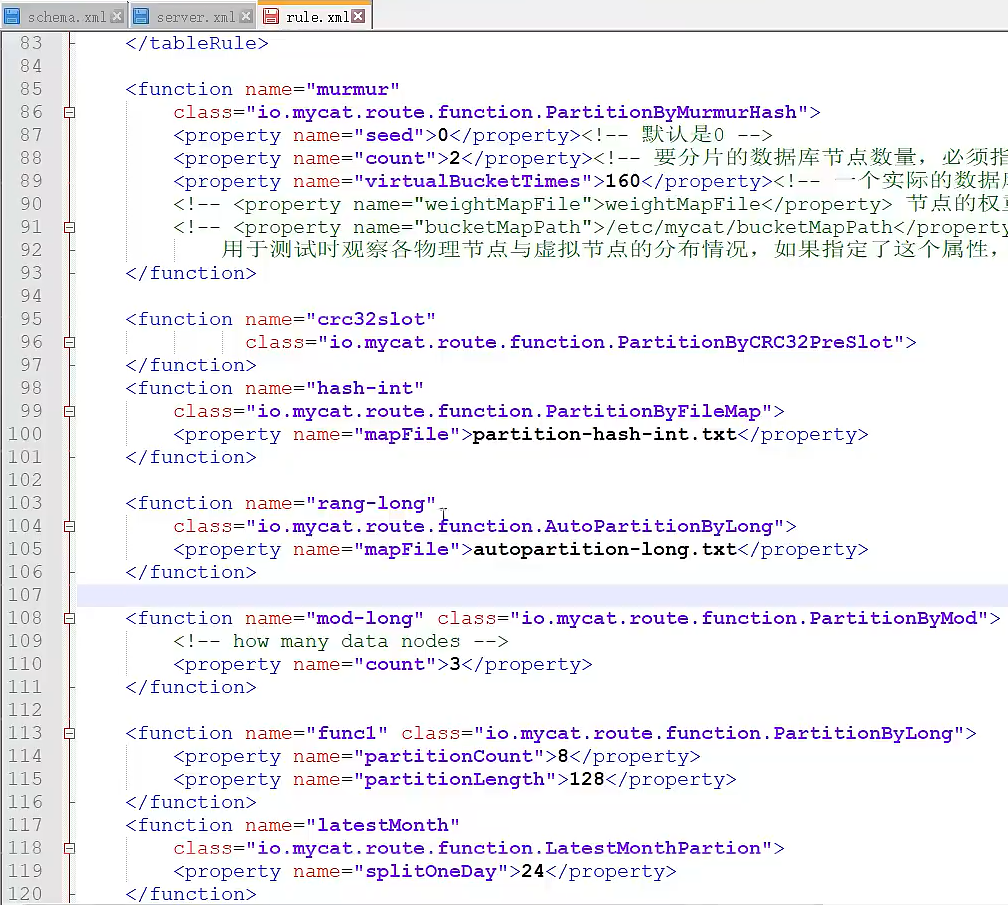
分片算法(rule.xml)
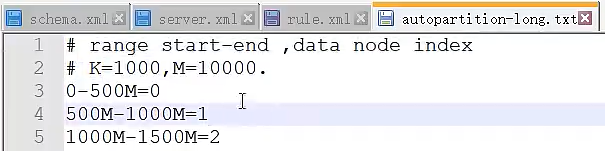
MyCat在垂直分表下,不支持多个分片节点的连表查询,如果有这个需求,只能把表设置成全局表(即该表和数据在所有分片节点都存在)。
思考
在可重复读的隔离级别下,分别开启两个事务A和B。在B事务里面插入一条记录的时候,A事务开启共享锁再去查询的时候,发现卡死了,直到B事务提交,A事务才继续执行,在B事务里面修改记录也一样会卡死。为什么A事务会卡死?
答:因为在事务修改的时候,会给对应的记录加上行锁(排他锁),只有在事务提交之后才会释放锁。所以A事务去读取时,因为有锁,所以就一直卡在那了,直到事务B提交释放锁,事务A才能够上锁,进而读取数据。
在串行化隔离级别下,事务B插入一条主id=13的数据,然后事务A去查询id=13的数据,发现卡住了。然后如果这种情况发生在可重复度的隔离级别下,事务A不会卡住,会返回空记录,但是如果事务A开启共享锁去查的话,事务A也会卡住。为什么会发生这种情况?
答:因为串行化的每一次查询都是当前读(即加锁了),然后事务B执行了插入,会有一个排他锁,所以查询的时候就会卡住。在RR隔离级别下,默认查询是快照读,所以就不会卡,但是加锁去读取,因为有排他锁,所以也会卡死。